Grid Computing
Last Updated :
21 Mar, 2023
Grid Computing can be defined as a network of computers working together to perform a task that would rather be difficult for a single machine. All machines on that network work under the same protocol to act as a virtual supercomputer. The task that they work on may include analyzing huge datasets or simulating situations that require high computing power. Computers on the network contribute resources like processing power and storage capacity to the network.
Grid Computing is a subset of distributed computing, where a virtual supercomputer comprises machines on a network connected by some bus, mostly Ethernet or sometimes the Internet. It can also be seen as a form of Parallel Computing where instead of many CPU cores on a single machine, it contains multiple cores spread across various locations. The concept of grid computing isn’t new, but it is not yet perfected as there are no standard rules and protocols established and accepted by people.
Working:
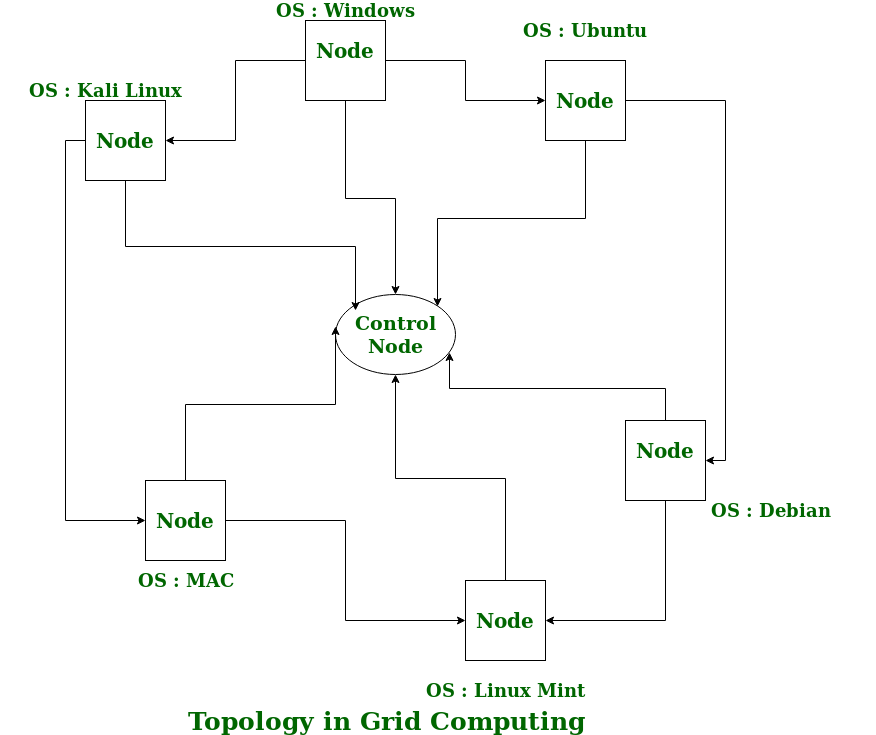
A Grid computing network mainly consists of these three types of machines
- Control Node: A computer, usually a server or a group of servers which administrates the whole network and keeps the account of the resources in the network pool.
- Provider: The computer contributes its resources to the network resource pool.
- User: The computer that uses the resources on the network.
When a computer makes a request for resources to the control node, the control node gives the user access to the resources available on the network. When it is not in use it should ideally contribute its resources to the network. Hence a normal computer on the node can swing in between being a user or a provider based on its needs. The nodes may consist of machines with similar platforms using the same OS called homogeneous networks, else machines with different platforms running on various different OSs called heterogeneous networks. This is the distinguishing part of grid computing from other distributed computing architectures.
For controlling the network and its resources a software/networking protocol is used generally known as Middleware. This is responsible for administrating the network and the control nodes are merely its executors. As a grid computing system should use only unused resources of a computer, it is the job of the control node that any provider is not overloaded with tasks.
Another job of the middleware is to authorize any process that is being executed on the network. In a grid computing system, a provider gives permission to the user to run anything on its computer, hence it is a huge security threat to the network. Hence a middleware should ensure that there is no unwanted task being executed on the network.
The meaning of the term Grid Computing has changed over the years, according to “The Grid: Blueprint for a new computing infrastructure” by Ian Foster and Carl Kesselman published in 1999, the idea was to consume computing power like electricity is consumed from a power grid. This idea is similar to the current concept of cloud computing, whereas now grid computing is viewed as a distributed collaborative network. Currently, grid computing is being used in various institutions to solve a lot of mathematical, analytical, and physics problems.
Advantages of Grid Computing:
- It is not centralized, as there are no servers required, except the control node which is just used for controlling and not for processing.
- Multiple heterogeneous machines i.e. machines with different Operating Systems can use a single grid computing network.
- Tasks can be performed parallelly across various physical locations and the users don’t have to pay for them (with money).
Disadvantages of Grid Computing:
- The software of the grid is still in the involution stage.
- A super-fast interconnect between computer resources is the need of the hour.
- Licensing across many servers may make it prohibitive for some applications.
- Many groups are reluctant with sharing resources.
- Trouble in the control node can come to halt in the whole network.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...