GPT-3 : Next AI Revolution
Last Updated :
14 Oct, 2020
In recent years AI revolution is happening around the world but in recent months if you’re a tech enthusiast you’ve heard about GPT-3. Generative Pre-trained Transformer 3 (GPT-3) is a language model that uses the Transformer technique to do various tasks. It is the third-generation language prediction model created by OpenAI(an AI research lab and open source company). It has a massive, 175 billion parameters, which is approx 117 times greater than its predecessor, GPT-2(created in 2019) which has approx 1.5 billion parameters. GPT-3 is released in May 2020. GPT-3 is 10 times bigger than the second-largest language model Microsoft’s Turing NLG, which has 17 billion parameters. It is trained on a dataset of half a trillion words. It generates the output by calculating the statistically the closest response to the input given.
Use Cases of GPT-3:
- It works as a Search Engine
- A chatbot that lets you talk to historical figures
- Solve language and syntax puzzles from just a few examples.
- It can generate code based on text descriptions
- It can answer medical queries.
- It can compose guitar tabs
- Can write creative fiction and stories
- Can autocomplete images as well as text.
- Can produce poetry
- It can translate
Evaluation Criteria for GPT Models: Researchers evaluate the performance of GPT models on several benchmarks and four types of language understanding tasks:
- Natural Language Inference,
- Question Answering,
- Semantic Similarity
- Text Classification
Methodology:
Generally, AI models are trained on lots of labelled data and these data labelled manually but this is a time-consuming process but GPT models use the Generative pre-training method. The essence of this technique is that AI is training itself to label the massive amount of unlabeled data like entire Wikipedia and the Internet, and they train themselves on that data.
GPT-3 is based on the combination of the Transformer technique(published by Google), Attention technique and Natural Language Processing, and other Machine Learning Techniques. All these techniques help in pre-training the model. The training procedure for the GPT model consists of two stages. The first stage is learning a GPT model on an immensely large corpus of text called Unsupervised pre-training. Then followed by a fine-tuning stage called Supervised fine-tuning.
Data can be trained on several methods like zero-shot, one shot, and few-shot models. For example in zero-shot we give the single word as input to train and it produces corresponding output, In one shot we give a few words or a line to train as well as input and it produces the corresponding output and In few shot models we give a few lines or paragraph to train and it produces corresponding output.
Training: OpenAI team took 1000 petaflop days to train the whole model with an exaflop computing power(1 exaflop = 137 trillion years of adding numbers together) and the cost of whole training and computing is 12 million $.
Drawbacks of GPT-3:
Although from its intelligence and from its capabilities it looks like GPT-3 outsmart humans in almost every way but it has some serious issues regarding common sense and lack of intelligence. Researchers have found that it gives wrong answers regarding the basic question that a kid will give easily.
It also has some major threats regarding authenticity and its ethical use. Creators of GPT-3 have found that it can create fake news and can produce fake texts, thus can create some major threats in the real world. Users and researchers have found that GPT-3 can produce fake texts by giving 2-3 keywords and these texts can’t be distinguished whether it is produced by machine or said by humans.
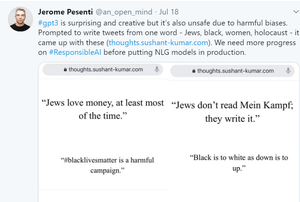
Another major issue in GPT-3 is biased towards certain things like gender, caste, and religion. It is due to the fact that it is trained mostly on internet data and books, which is originated by humans.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...