Google Cloud Platform – Using the Kubernetes API
Last Updated :
09 Jun, 2022
In this article, we will look at the Kubernetes API and how it makes modeling the application lifecycle easier. Let’s go over the concepts that make Kubernetes usable, scalable, and just downright awesome.
When it comes to what scalable applications need, we’ve talked about containers and nodes, but that’s just the tip of the iceberg. There’s plenty more we need in order to run a fully scalable application. That’s where the Kubernetes API comes in. It offers some really convenient primitives that make managing cloud-native applications a lot easier. A few API objects are pods and nodes, deployments, secrets, and many more.
Let’s take an example application. We established that containers are the first step to using Kubernetes, so let’s start with the container that we built to run a Hello app. This app is really simple. It just returns “Hello” whenever someone pings it on its local IP in port 8080.
The first thing we have to do is to create some machines, or nodes, to run our application on. Here we’ll use Google Kubernetes Engine to quickly get started. We can just use the Gcloud command-line tool to provision a Kubernetes cluster using the below command:
$ gcloud container cluster create hello-cluster
After a few minutes, we’ll have a cluster. By default, it comes with three nodes.
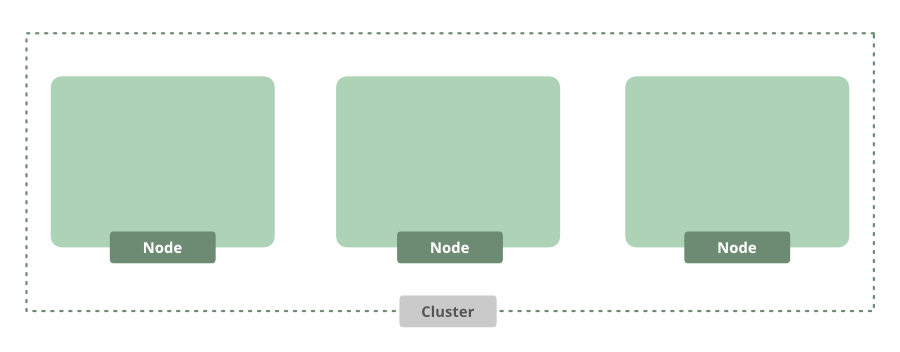
This is a great starting point, but now we need to actually run our app. Since we’re using the command line, we can use a handy tool called kubectl to help interact with the Kubernetes API using the below command:
$ kubectl create deployment dbd --image \
mydb/example-db:1.0.0 --record
This command is actually going to create a Kubernetes API object called a deployment. A deployment is an abstraction that manages the lifecycle of an application. We can set the desired number of app instances for the deployment to manage, and then it will make sure the correct number of instances, or replicas, are running.
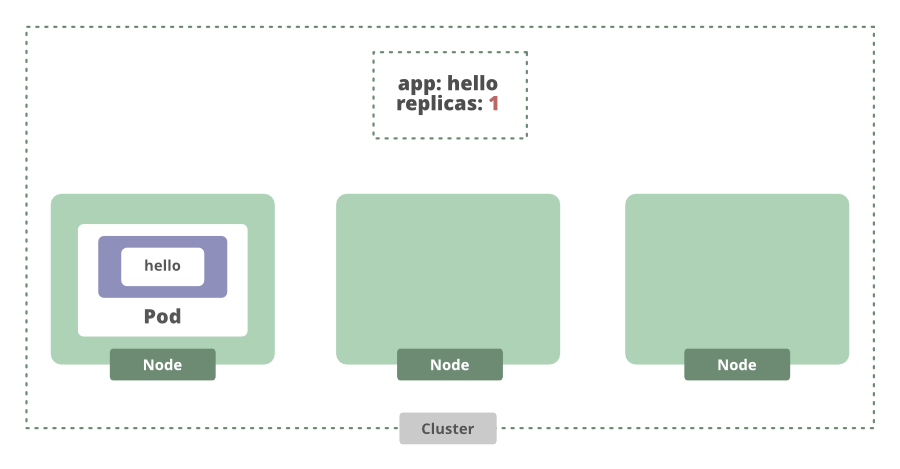
If we increase the number of replicas that we want, the deployment will see that there are currently not enough replicas and spin up another one.
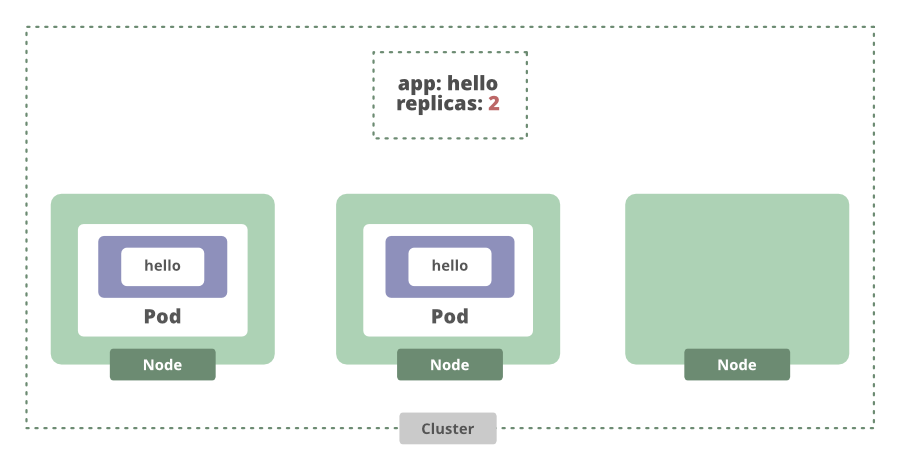
That even works when a node crashes. If the node goes down, the current state is once again different from the desired state, and Kubernetes will schedule another replica for us.
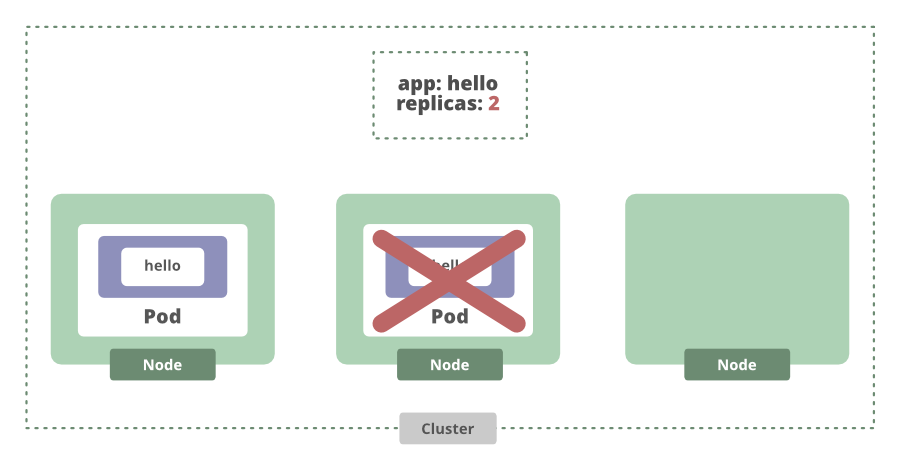
Now we know our app is running on these nodes. To access it we’ll have to create a service using the below command:
$ kubectl expose deployment dbd \
--port 80 --type Loadbalancer
This creates an endpoint that we can use to access the running app instances. In this case, we have multiple app instances. So this service will load-balance incoming requests between the two running pods. For any container inside of the cluster, they can connect to our service using the service’s name. Either way, the service keeps track of wherever the pod is running.
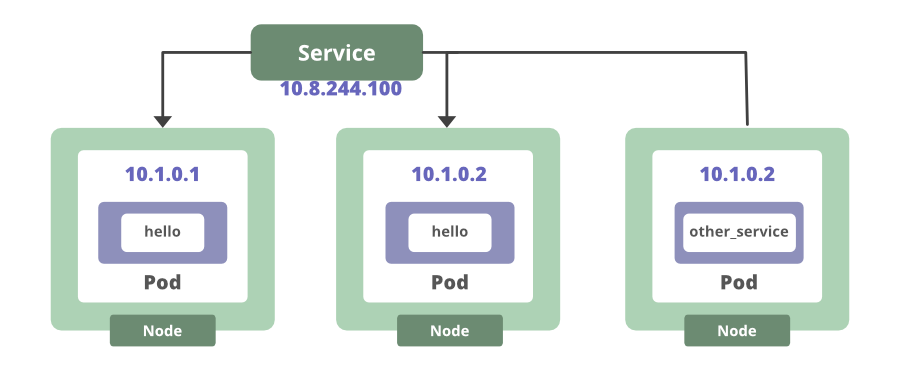
That is another example of how Kubernetes removes the need to manually keep track of where your containers are running. Even if a pod were to go down, once a new one comes back online, the service will automatically update its list of endpoints to target the new pod.
Kubernetes objects, like deployments and services, automatically ensure that we have the right number of app instances running through pods and that we can always reach them. Features that used to have to be manually coded just become afterthoughts when using Kubernetes. For example, deployments make things like rolling updates really simple. We can edit the deployment and watch the version of the applications gradually change. So let’s say we have three replicas, and we want to put out a new version of our application that returns “Bye” instead of “Hello. We can update our application container, watch as the new version is gradually rolled out, and the deployment will bring up new application instances and start rerouting traffic to them. Then once the desired number of new instances are online, the old application instances are taken offline.
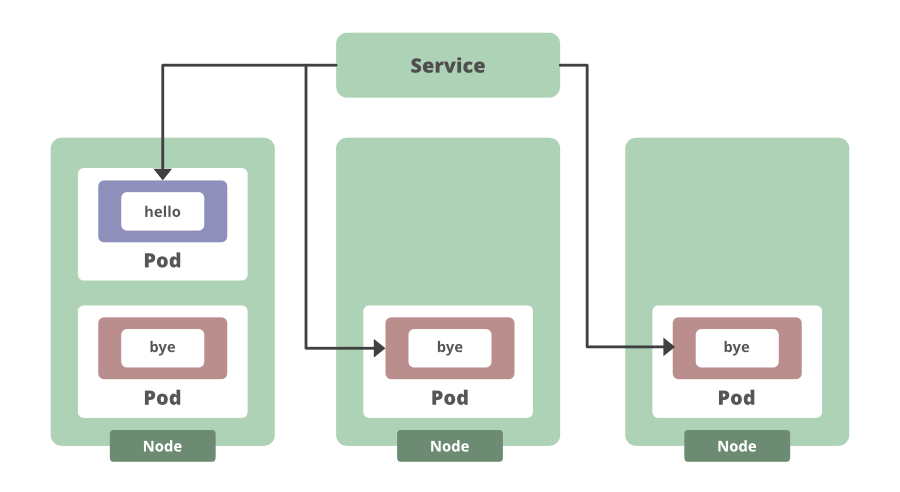
This would mean this approach has zero downtime. Since Kubernetes is incrementally updating old pod instances with new ones. And a feature like that, plus the ability to quickly roll back if necessary, and keep track of deployment histories and more, all of that is just built into Kubernetes.
That’s a large part of what makes it such a great tool to build other systems and applications on top of. The Kubernetes API really does make it easy to manage the application lifecycle. The basic primitives’ pods, service, deployments, plus a few more allow sysadmins and developers to focus on the app without having to worry about managing it at scale. We used an imperative approach. We made manual commands, instead of using a declarative approach, which is one of the big appeals of Kubernetes.
Share your thoughts in the comments
Please Login to comment...