Getting started with Kaggle : A quick guide for beginners
Last Updated :
18 Oct, 2019
Kaggle is an online community of Data Scientists and Machine Learning Engineers which is owned by Google. A general feeling of beginners in the field of Machine Learning and Data Science towards the website is of hesitance. This feeling mainly arises because of the misconceptions that the outside people have about the website. Here are some of them –
Kaggle is a Machine Learning competitions hosting website – This misconception is widespread because many organizations host Machine Learning competitions either to recruit Data Scientists or to get a solution to a problem which it is facing. Users and teams with the best solutions are often rewarded with cash prizes. Alongside hosting competitions, the website also hosts a plethora of datasets. Users are also rewarded for the best datasets.

Only PhD’s and Data Scientists can win the competitions – This is a story of a high-school kid who was very interested in the subject taught himself. He did not learn about the complicated mathematics behind the algorithms and instead got a logical sense of the techniques.
People think that they are not good enough to enter the competitions – As a learning process, one should focus on the Exploratory part and feature engineering of a Machine Learning project.
To get started with Kaggle, one should follow a general outline of steps –
Step #1: Picking a Programming Language –
Python and R are the two most famous programming languages for Data Science and Machine Learning. Usually, if a person is from a development background, Python is preferred while if a person is from a statistical/analytic background, R is preferred. On a general consensus, Python is preferred because it is a general-purpose programming language and can bend according to the needs of the user.
Step #2: Learning the Exploratory Analysis Basics –
As stated above, one should focus on doing the Exploratory analysis of the given data. One should also learn how to visualise the data and generally, the Python libraries Matplotlib and Seaborn are considered to great starting points.
Step #3: Learning the basics of training a model –
Before getting into the depths of Kaggle, one should have a little experience of training a learning model. Generally the Python library Sklearn is considered the best for this purpose.
Step #4: Getting into Kaggle –
Kaggle has a lot of different categories of competitions. One of them is the ‘Getting Started’ category which are structured like the main money rewarding competitions. These competitions have easier datasets and community-created tutorials.
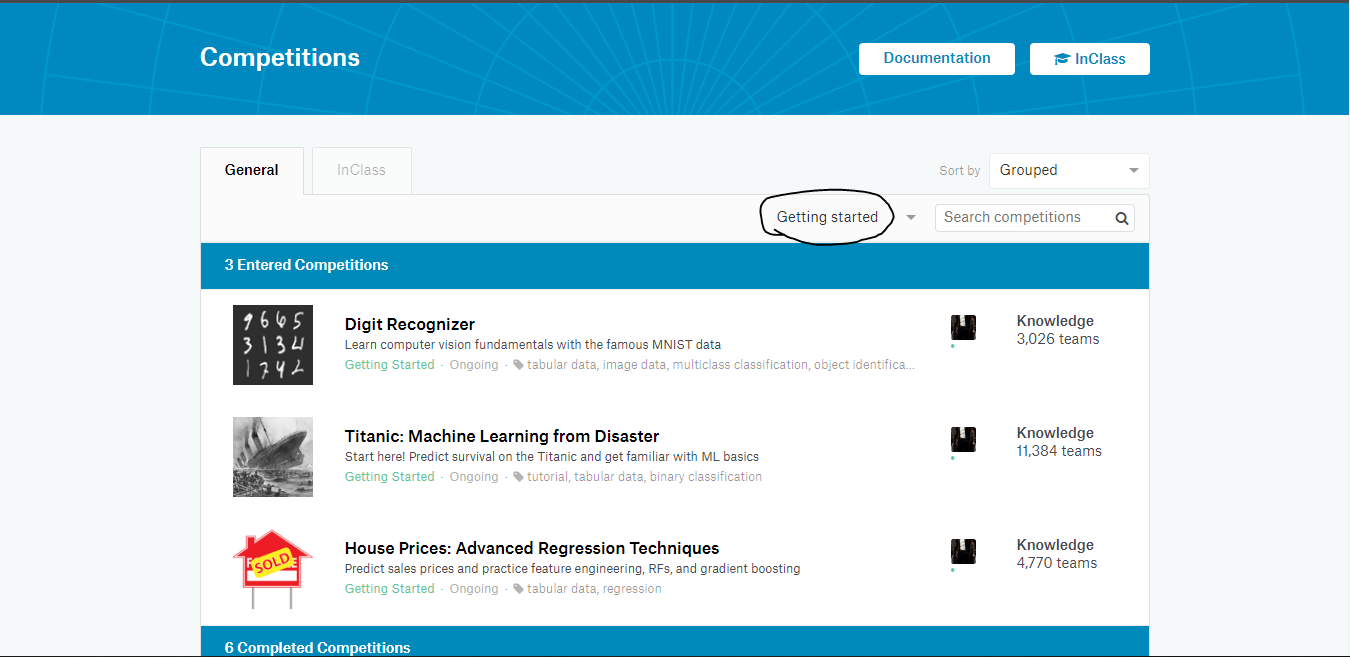
Step #5: Compete to learn –
One should compete on the website with an intent to learn and not to earn money.
Step #6: Refer to upvoted Kernels –
Kernels in Kaggle are a way to share your virtual Jupyter notebooks and run them on the cloud. Many winners have public interviews about their thinking process. One can refer to the other upvoted kernels to learn and broaden their thinking space.
Kaggle is a great stepping stone and should be a part of every upcoming Machine Learning engineer and Data Scientist.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...