Find tags by CSS class using BeautifulSoup
Last Updated :
12 Jan, 2024
BeautifulSoup is a Python library for pulling data out of HTML and XML files. When working with HTML documents, we often need to extract specific elements based on their CSS classes. In this article, we will discuss how to find tags by CSS using BeautifulSoup. We are given an HTML document, we need to find and extract tags from the document using the CSS class.
Examples
HTML Document:
<html>
<head>
<title> Geeksforgeeks </title>
</head>
<body>
<div class="ext" >Extract this tag</div>
</body>
</html>
Output:
<div class="ext" >Extract this tag</div>
Required Modules
bs4: It is a Python library used to scrape data from HTML, XML, and other markup languages.
Make sure you have pip installed on your system. Run the following command in the terminal to install this library-
pip install bs4
or
pip install beautifulsoup4
Find Tags by CSS Class Using BeautifulSoup
Below are the ways by which we can find tags using BeautifulSoup in Python:
- Using find() method
- Using find_all() function
- Using Regular Expressions
- Using the User-Defined function
- From a Website
Example 1: Find the Tag Using find() Method
In this example, a function find_tags_from_class is defined to parse an HTML document using BeautifulSoup and extract a specific <div> tag with a given CSS class. The function is called with a sample HTML string to demonstrate the extraction process.
Python3
from bs4 import BeautifulSoup
HTML_DOC =
def find_tags_from_class(html):
soup = BeautifulSoup(html, "html.parser")
div = soup.find("div", class_= "ext")
print(div)
find_tags_from_class(HTML_DOC)
|
Output:

Example 2: Find All the Tags Using find_all() Method
In this example, a function find_tags_from_class is defined to parse an HTML table using BeautifulSoup and extract all <td> tags with a specific CSS class “table-row”. The function iterates through the extracted tags and prints each row to the console.
Python3
from bs4 import BeautifulSoup
HTML_DOC =
def find_tags_from_class(html):
soup = BeautifulSoup(html, "html.parser")
rows = soup.find_all("td", class_= "table-row")
for row in rows:
print(row)
find_tags_from_class(HTML_DOC)
|
Output

Example 3: Finding Tags by CSS class Using Regular Expressions
In this example, a function find_tags_from_class is defined to parse an HTML table using BeautifulSoup and extract all <td> tags whose CSS class names end with “row” using a regular expression pattern. The function iterates through the extracted tags and prints each row to the console.
Python3
from bs4 import BeautifulSoup
import re
HTML_DOC =
def find_tags_from_class(html):
soup = BeautifulSoup(html, "html.parser")
rows = soup.find_all("td", class_= re.compile("row$"))
for row in rows:
print(row)
find_tags_from_class(HTML_DOC)
|
Output

Explanation
<td class="table-row"> This is row 2 </td>
<td class="table-row"> This is row 4 </td>
Above two tags class name ends with “row”. Therefore, they are extracted. Other tags class name doesn’t end with “row”. Therefore, they are not extracted.
Example 4: Finding Tags by CSS Class Using the User-Defined Function
In this example, a user-defined function has_three_characters is defined to check if a CSS class name is not None and has a length of 3 characters. The function find_tags_from_class parses an HTML table using BeautifulSoup and extracts all <td> tags based on the condition specified by the user-defined function. The function then iterates through the extracted tags and prints each valid row to the console.
Python3
from bs4 import BeautifulSoup
HTML_DOC =
def has_three_characters(css_class):
return css_class is not None and len(css_class) == 3
def find_tags_from_class(html):
soup = BeautifulSoup(html, "html.parser")
rows = soup.find_all("td", class_= has_three_characters)
for row in rows:
print(row)
find_tags_from_class(HTML_DOC)
|
Output:

Example 5: Finding Tags by CSS Class from a Website
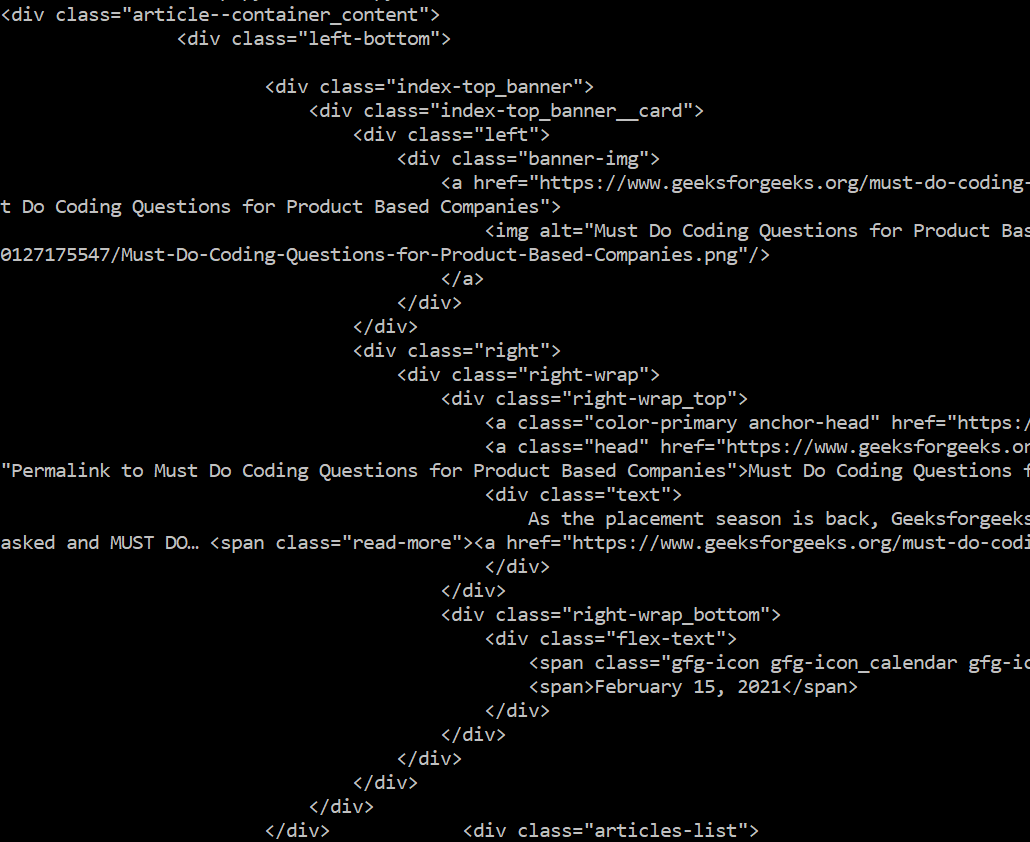
In this example, the requests module is used to fetch the HTML content of the GeeksforGeeks website. The function find_tags_from_class parses the fetched HTML content using BeautifulSoup with the ‘html5lib’ parser and extracts a specific <div> tag with the CSS class “article–container_content”. The extracted tag is then printed to the console.
Python3
from bs4 import BeautifulSoup
import requests
import requests
HTML_DOC = requests.get(URL)
def find_tags_from_class(html):
soup = BeautifulSoup(html.content, "html5lib")
div = soup.find("div", class_= "article--container_content")
print(div)
find_tags_from_class(HTML_DOC)
|
Output:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...