Filters in Linux
Last Updated :
13 Jul, 2021
Filters are programs that take plain text(either stored in a file or produced by another program) as standard input, transforms it into a meaningful format, and then returns it as standard output. Linux has a number of filters. Some of the most commonly used filters are explained below:
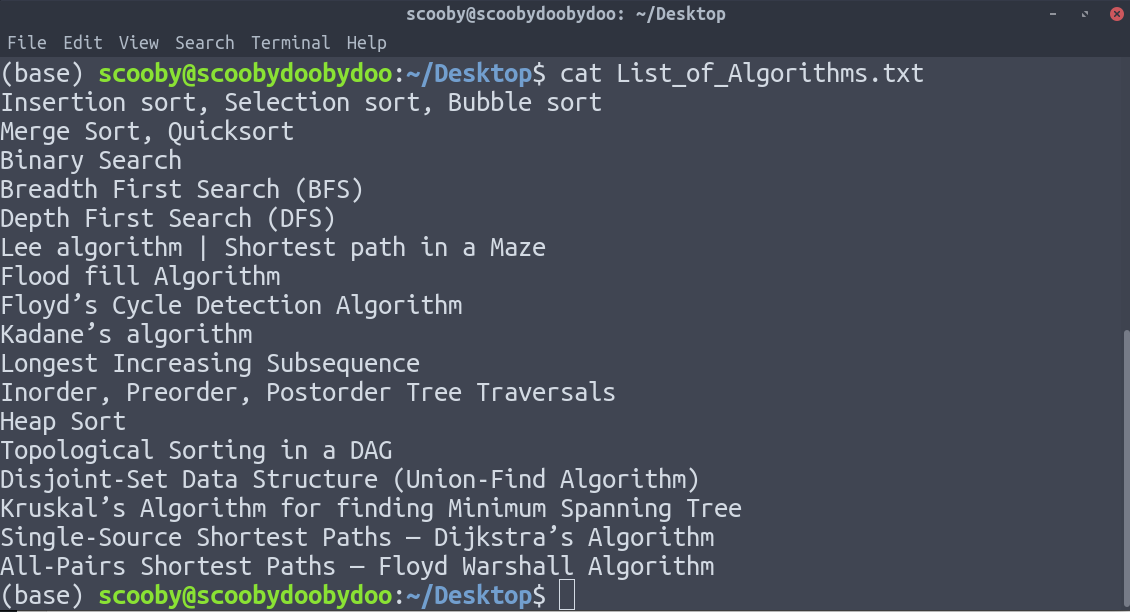
1. cat : Displays the text of the file line by line.
Syntax:
cat [path]
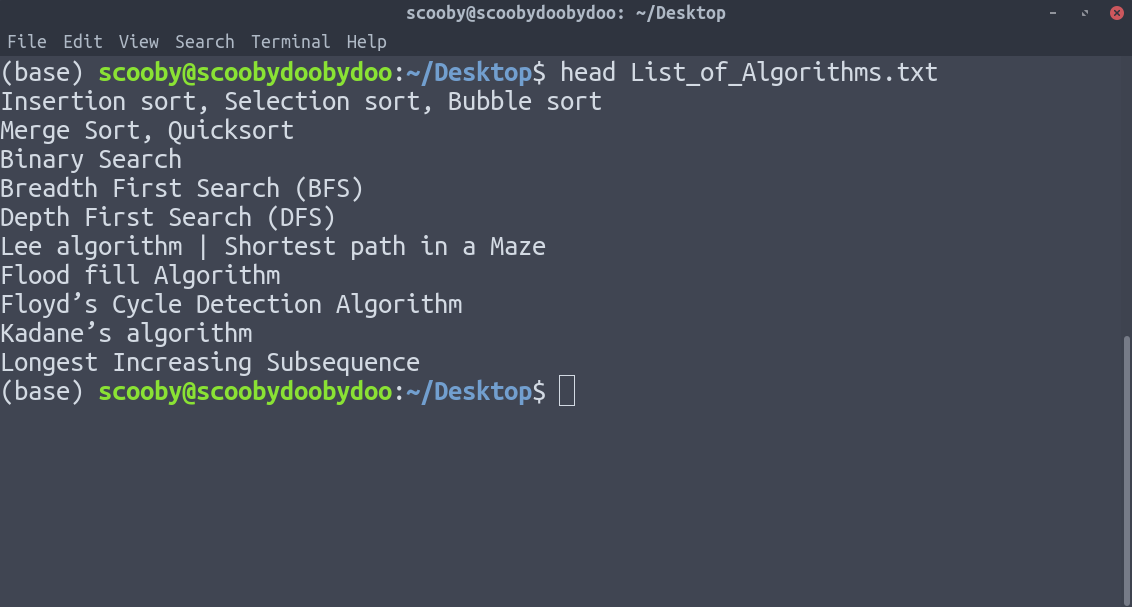
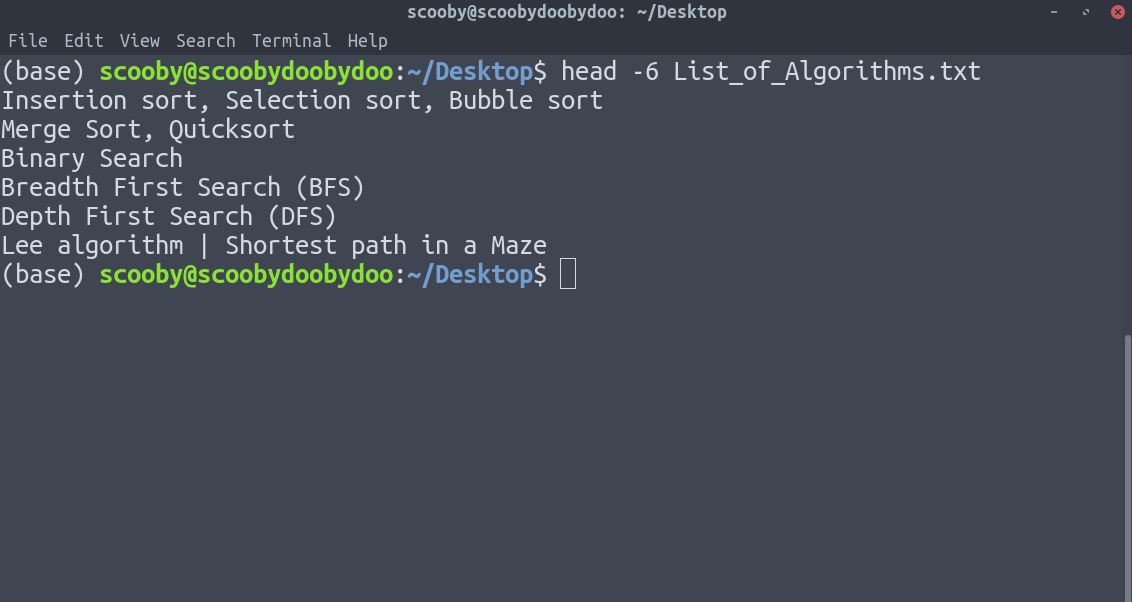
2. head : Displays the first n lines of the specified text files. If the number of lines is not specified then by default prints first 10 lines.
Syntax:
head [-number_of_lines_to_print] [path]
3. tail : It works the same way as head, just in reverse order. The only difference in tail is, it returns the lines from bottom to up.
Syntax:
tail [-number_of_lines_to_print] [path]
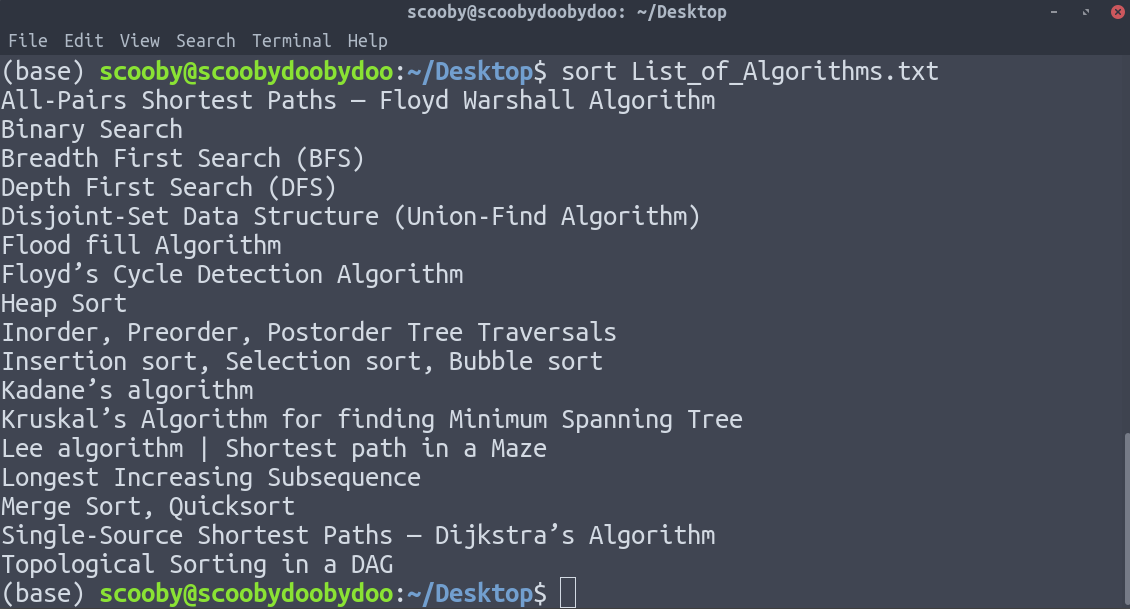
4. sort : Sorts the lines alphabetically by default but there are many options available to modify the sorting mechanism. Be sure to check out the main page to see everything it can do.
Syntax:
sort [-options] [path]
5. uniq : Removes duplicate lines. uniq has a limitation that it can only remove continuous duplicate lines(although this can be fixed by the use of piping). Assuming we have the following data.
Syntax:
uniq [options] [path]
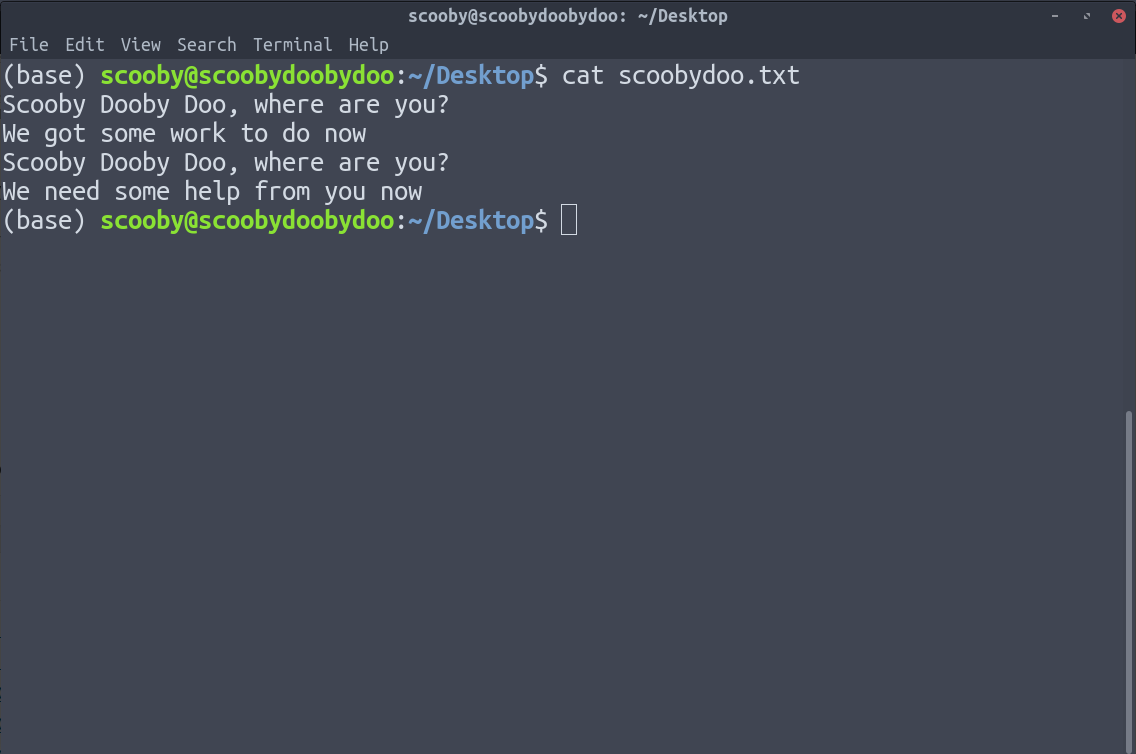
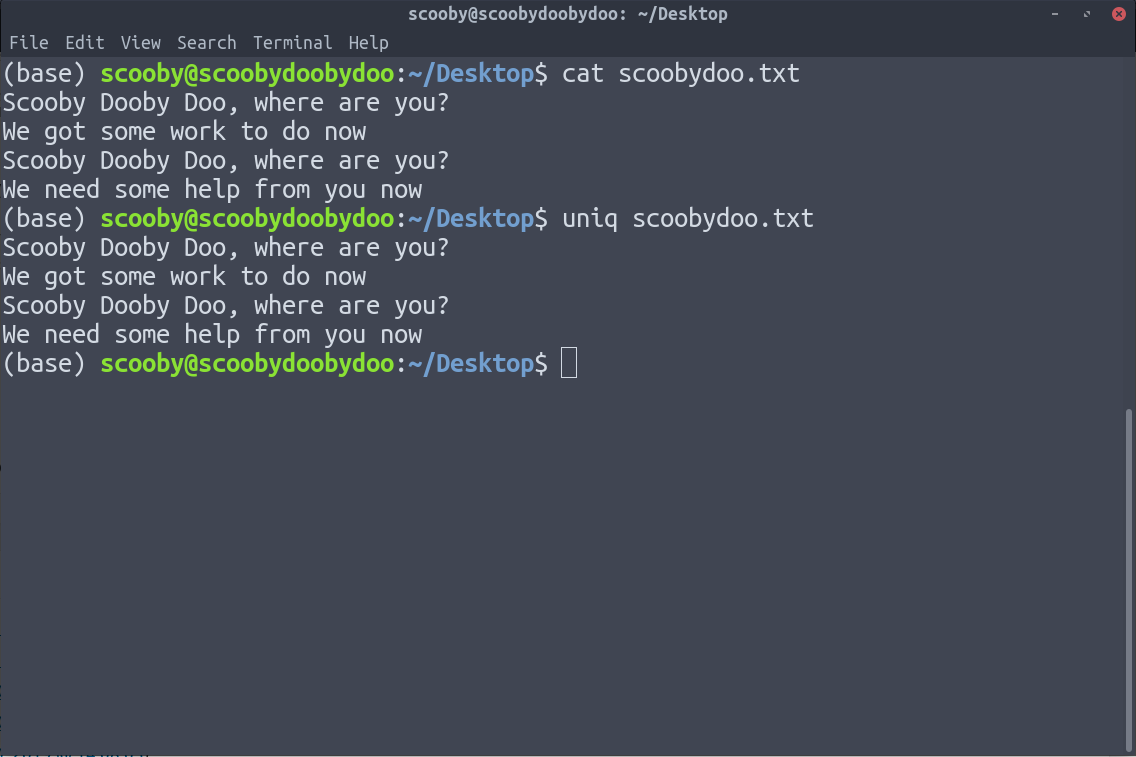
You can see that applying uniq doesn’t remove any duplicate lines, because uniq only removes duplicate lines which are together.
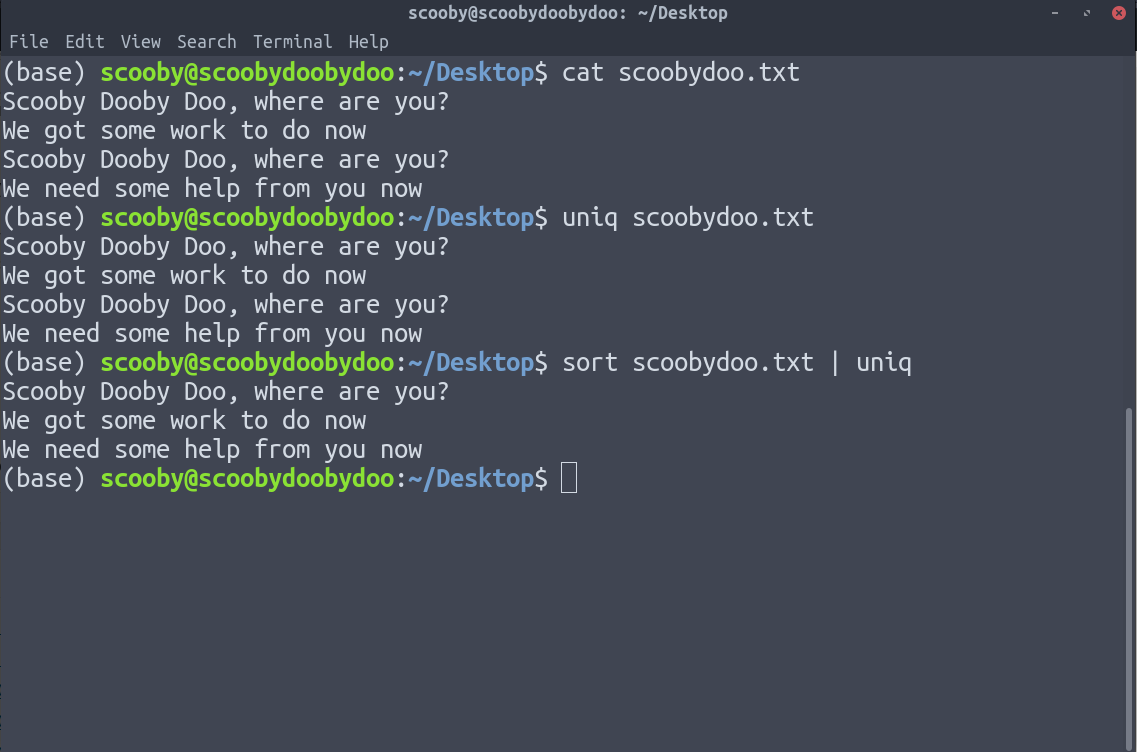
When applying uniq to sorted data, it removes the duplicate lines because, after sorting data, duplicate lines come together.
6. wc : wc command gives the number of lines, words and characters in the data.
Syntax:
wc [-options] [path]
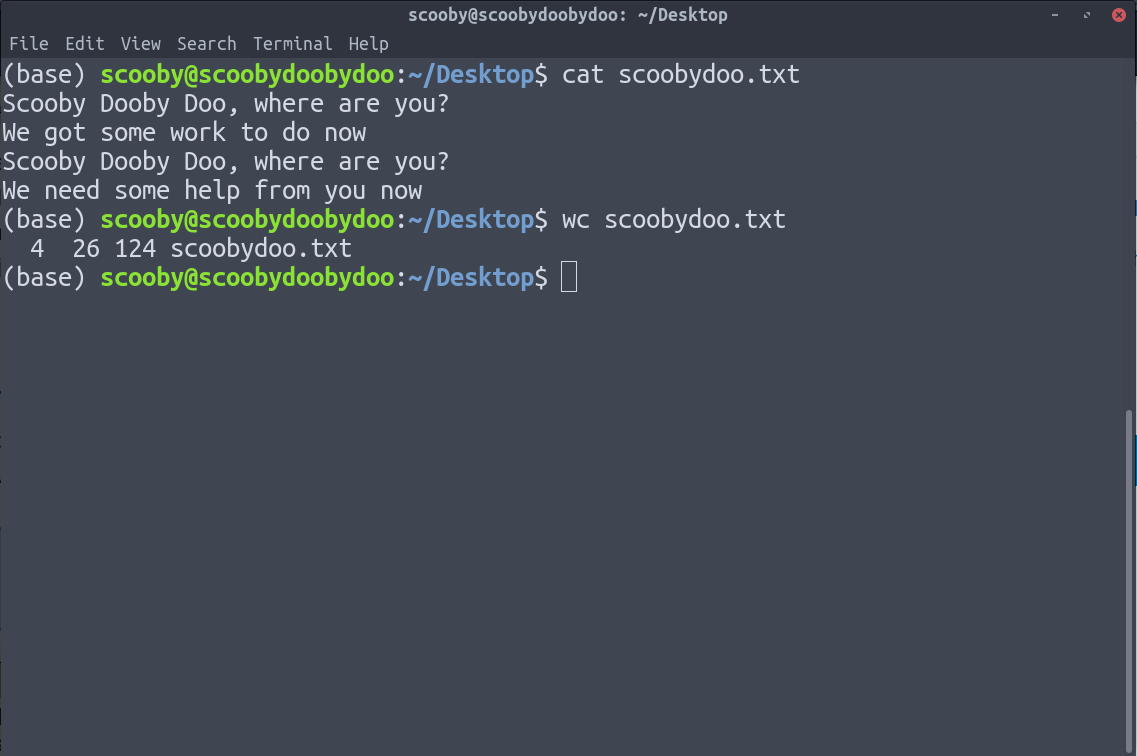
In above image the wc gives 4 outputs as:
- number of lines
- number of words
- number of characters
- path
7. grep : grep is used to search a particular information from a text file.
Syntax:
grep [options] pattern [path]
Below are the two ways in which we can implement grep.
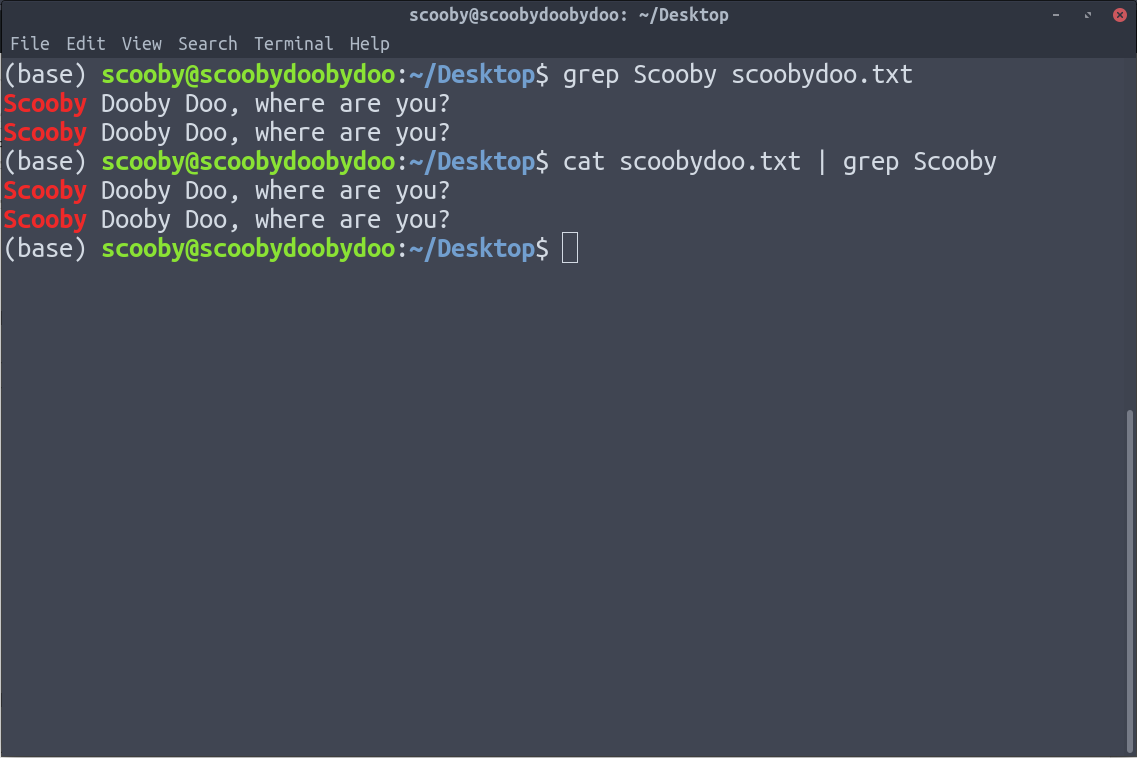
8. tac : tac is just the reverse of cat and it works the same way, i.e., instead of printing from lines 1 through n, it prints lines n through 1. It is just reverse of cat command.
Syntax:
tac [path]
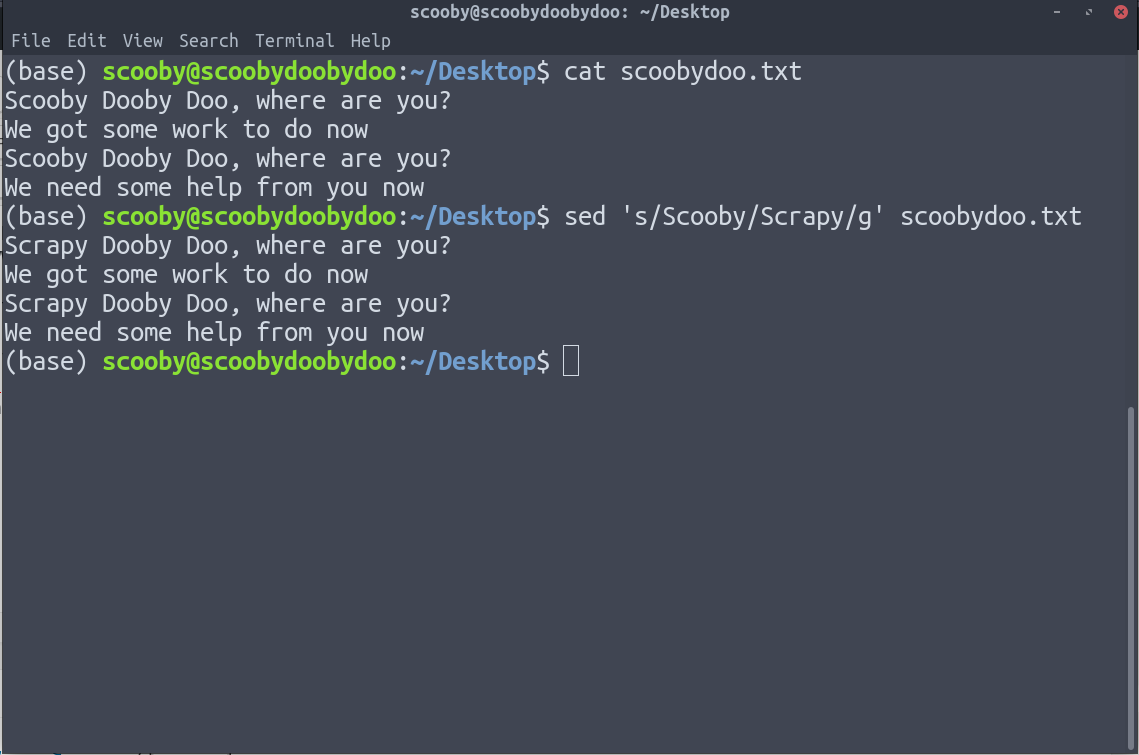
9. sed : sed stands for stream editor. It allows us to apply search and replace operation on our data effectively. sed is quite an advanced filter and all its options can be seen on its man page.
Syntax:
sed [path]
The expression we have used above is very basic and is of the form ‘s/search/replace/g’
In the above image, we can clearly see that Scooby is replaced by Scrapy.
10. nl : nl is used to number the lines of our text data.
Syntax:
nl [-options] [path]
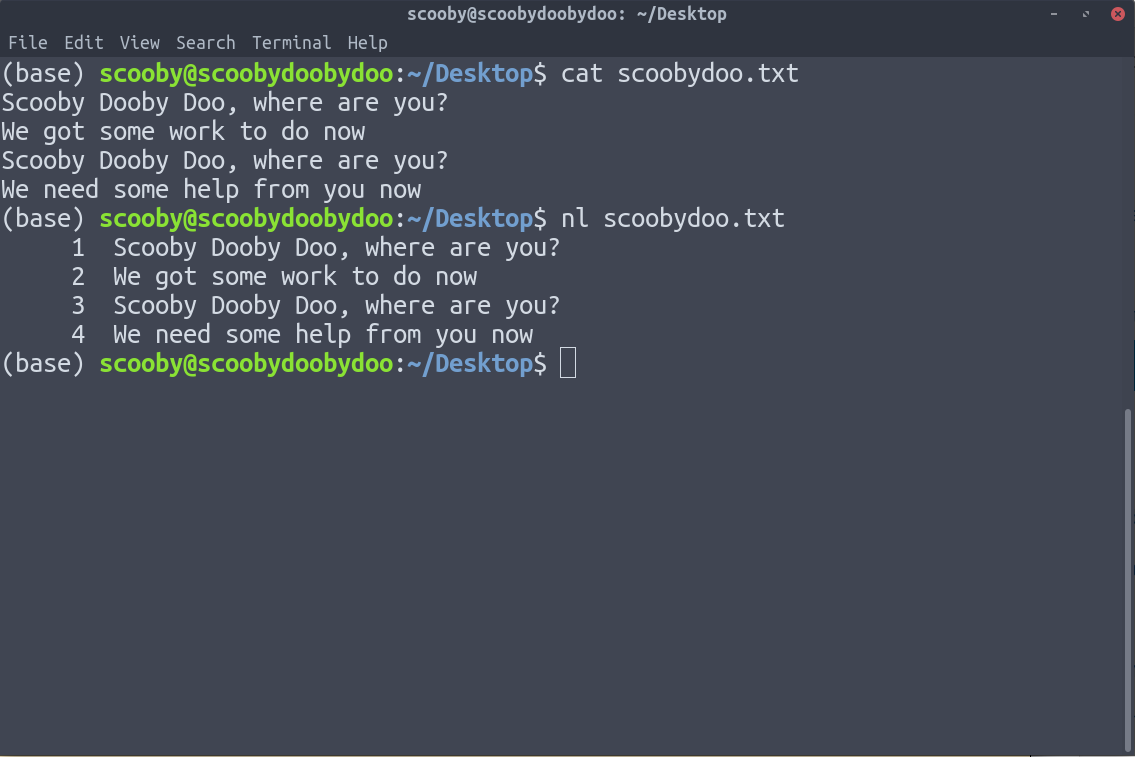
It can clearly be seen in the above image that the lines have been numbered
Share your thoughts in the comments
Please Login to comment...