File Systems in Operating System
Last Updated :
04 Dec, 2023
A computer file is defined as a medium used for saving and managing data in the computer system. The data stored in the computer system is completely in digital format, although there can be various types of files that help us to store the data.
What is a File System?
A file system is a method an operating system uses to store, organize, and manage files and directories on a storage device. Some common types of file systems include:
- FAT (File Allocation Table): An older file system used by older versions of Windows and other operating systems.
- NTFS (New Technology File System): A modern file system used by Windows. It supports features such as file and folder permissions, compression, and encryption.
- ext (Extended File System): A file system commonly used on Linux and Unix-based operating systems.
- HFS (Hierarchical File System): A file system used by macOS.
- APFS (Apple File System): A new file system introduced by Apple for their Macs and iOS devices.
A file is a collection of related information that is recorded on secondary storage. Or file is a collection of logically related entities. From the user’s perspective, a file is the smallest allotment of logical secondary storage.
The name of the file is divided into two parts as shown below:
- name
- extension, separated by a period.
Issues Handled By File System
We’ve seen a variety of data structures where the file could be kept. The file system’s job is to keep the files organized in the best way possible.
A free space is created on the hard drive whenever a file is deleted from it. To reallocate them to other files, many of these spaces may need to be recovered. Choosing where to store the files on the hard disc is the main issue with files one block may or may not be used to store a file. It may be kept in the disk’s non-contiguous blocks. We must keep track of all the blocks where the files are partially located.
Files Attributes And Their Operations
|
Name
|
Doc
|
Create
|
|
Type
|
Exe
|
Open
|
|
Size
|
Jpg
|
Read
|
|
Creation Data
|
Xis
|
Write
|
|
Author
|
C
|
Append
|
|
Last Modified
|
Java
|
Truncate
|
|
protection
|
class
|
Delete
|
|
|
|
Close
|
|
Executable
|
exe, com, bin
|
Read to run machine language program
|
|
Object
|
obj, o
|
Compiled, machine language not linked
|
|
Source Code
|
C, java, pas, asm, a
|
Source code in various languages
|
|
Batch
|
bat, sh
|
Commands to the command interpreter
|
|
Text
|
txt, doc
|
Textual data, documents
|
|
Word Processor
|
wp, tex, rrf, doc
|
Various word processor formats
|
|
Archive
|
arc, zip, tar
|
Related files grouped into one compressed file
|
|
Multimedia
|
mpeg, mov, rm
|
For containing audio/video information
|
|
Markup
|
xml, html, tex
|
It is the textual data and documents
|
|
Library
|
lib, a ,so, dll
|
It contains libraries of routines for programmers
|
|
Print or View
|
gif, pdf, jpg
|
It is a format for printing or viewing an ASCII or binary file.
|
File Directories
The collection of files is a file directory. The directory contains information about the files, including attributes, location, and ownership. Much of this information, especially that is concerned with storage, is managed by the operating system. The directory is itself a file, accessible by various file management routines.
Below are information contained in a device directory.
- Name
- Type
- Address
- Current length
- Maximum length
- Date last accessed
- Date last updated
- Owner id
- Protection information
The operation performed on the directory are:
- Search for a file
- Create a file
- Delete a file
- List a directory
- Rename a file
- Traverse the file system
Advantages of Maintaining Directories
- Efficiency: A file can be located more quickly.
- Naming: It becomes convenient for users as two users can have same name for different files or may have different name for same file.
- Grouping: Logical grouping of files can be done by properties e.g. all java programs, all games etc.
Single-Level Directory
In this, a single directory is maintained for all the users.
- Naming problem: Users cannot have the same name for two files.
- Grouping problem: Users cannot group files according to their needs.
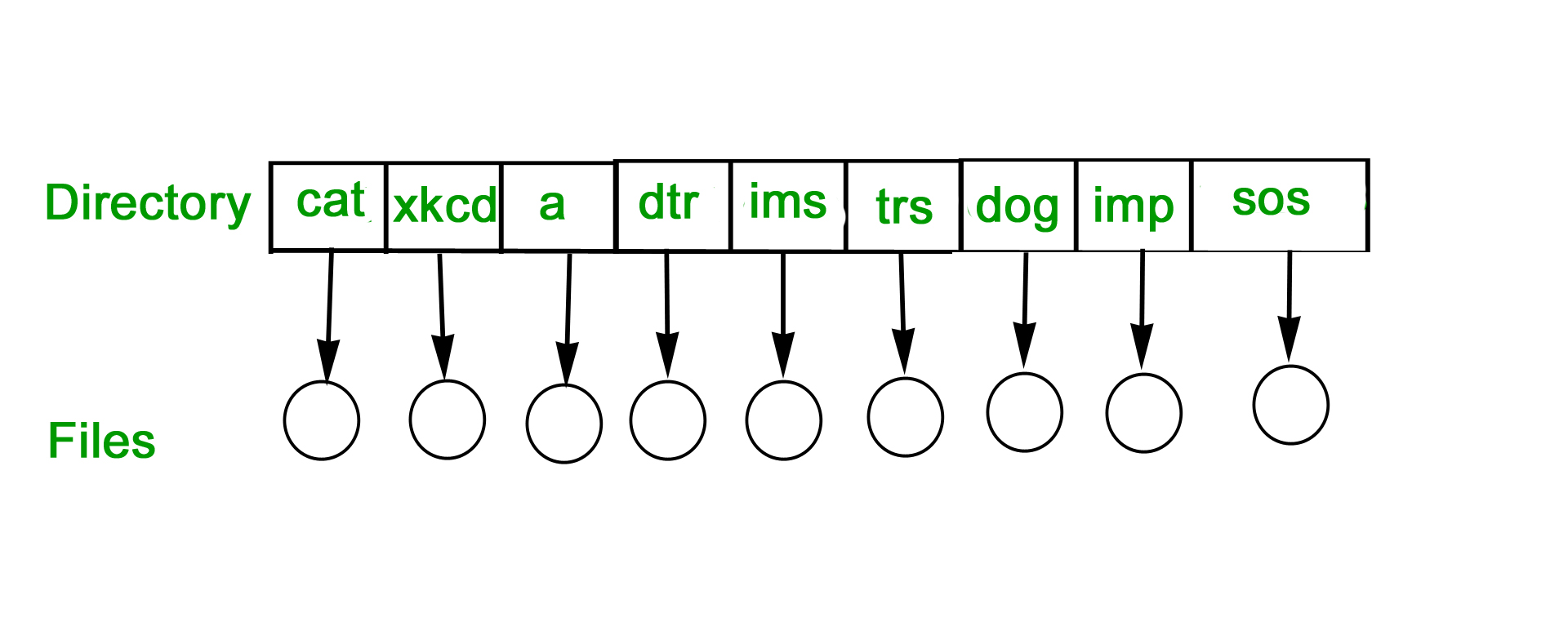 Two-Level Directory
Two-Level Directory
In this separate directories for each user is maintained.
- Path name: Due to two levels there is a path name for every file to locate that file.
- Now, we can have the same file name for different users.
- Searching is efficient in this method.
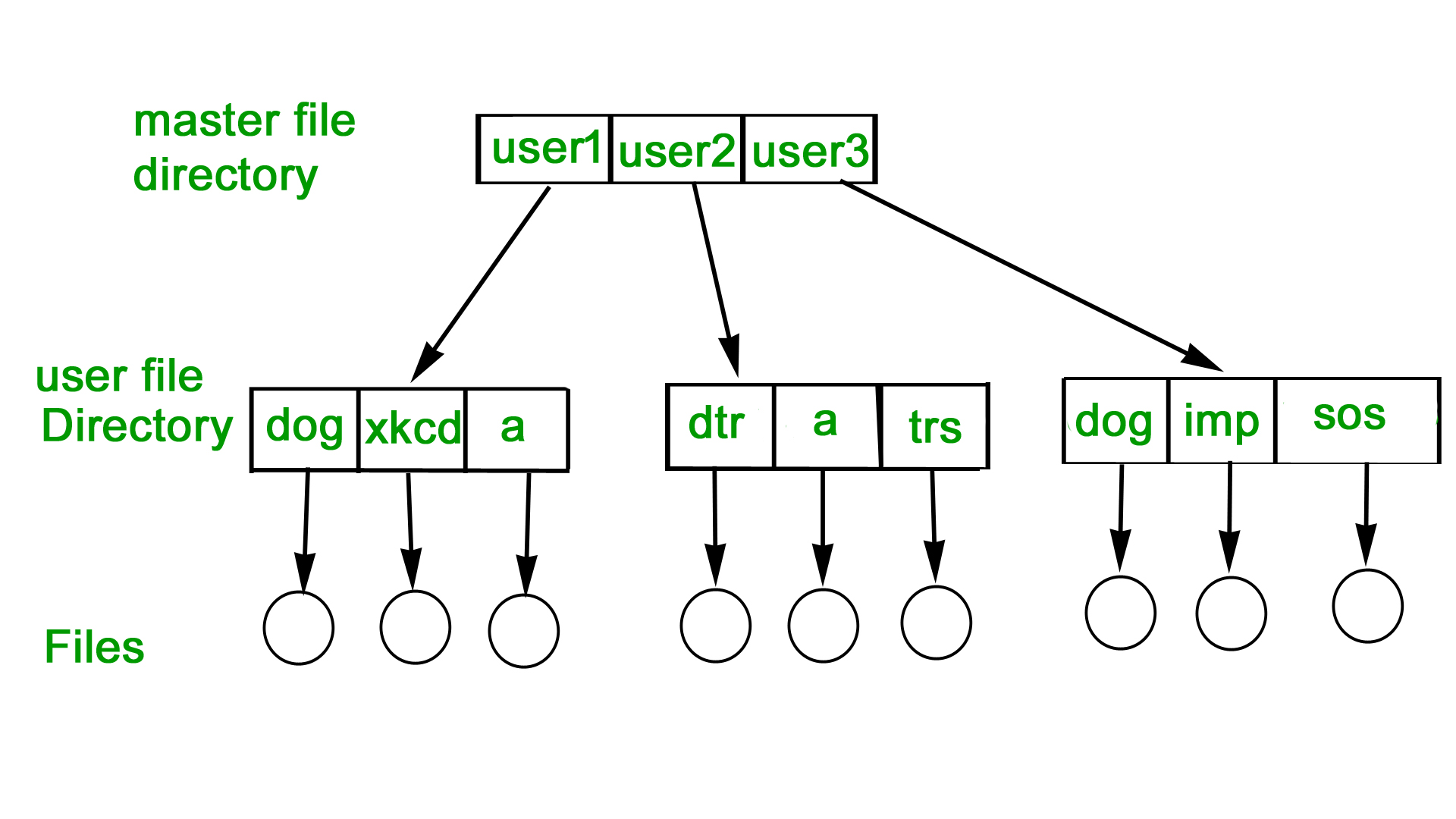 Tree-Structured Directory
Tree-Structured Directory
The directory is maintained in the form of a tree. Searching is efficient and also there is grouping capability. We have absolute or relative path name for a file.
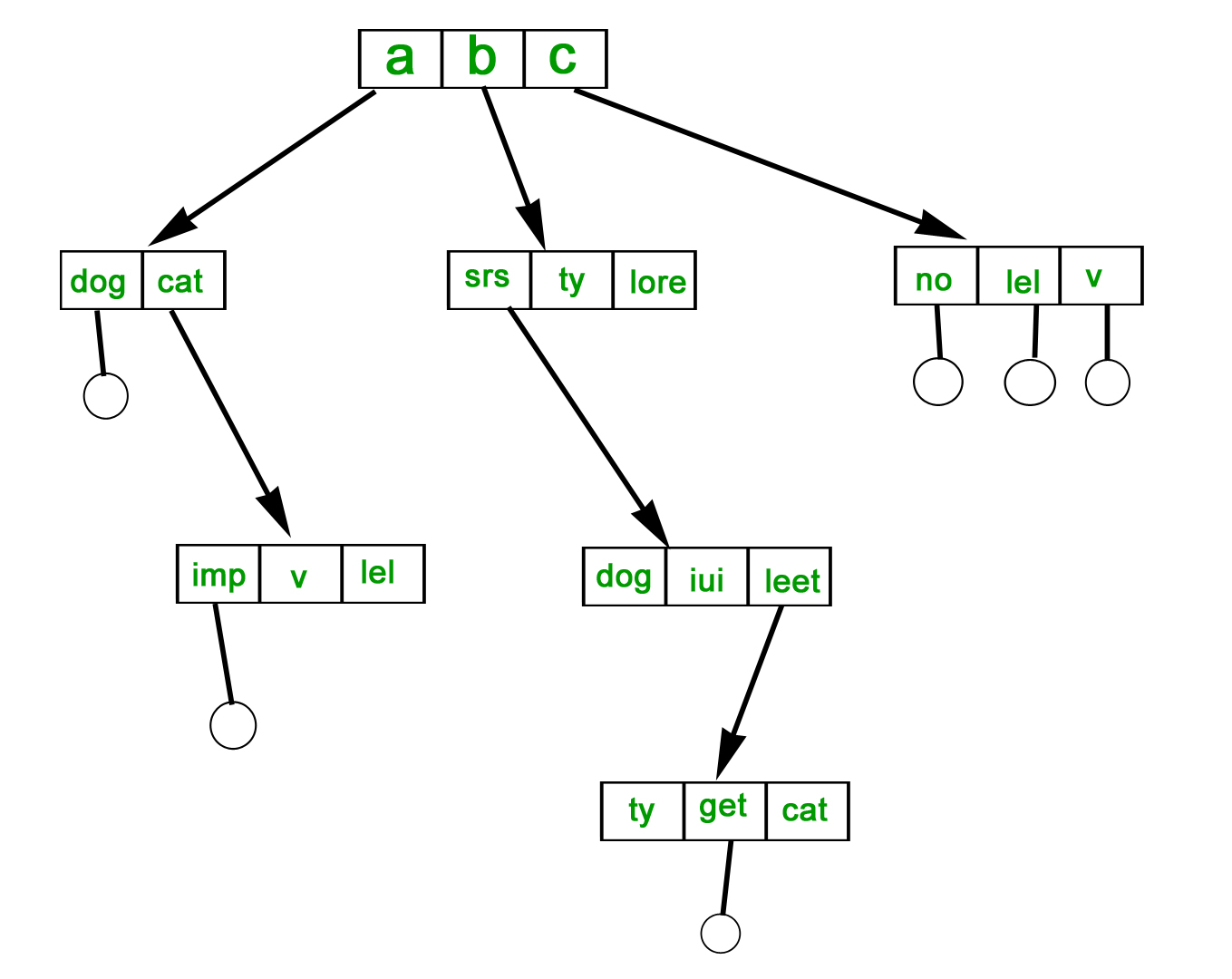 File Allocation Methods
File Allocation Methods
There are several types of file allocation methods. These are mentioned below.
- Continuous Allocation
- Linked Allocation(Non-contiguous allocation)
- Indexed Allocation
Continuous Allocation
A single continuous set of blocks is allocated to a file at the time of file creation. Thus, this is a pre-allocation strategy, using variable size portions. The file allocation table needs just a single entry for each file, showing the starting block and the length of the file. This method is best from the point of view of the individual sequential file. Multiple blocks can be read in at a time to improve I/O performance for sequential processing. It is also easy to retrieve a single block. For example, if a file starts at block b, and the ith block of the file is wanted, its location on secondary storage is simply b+i-1.
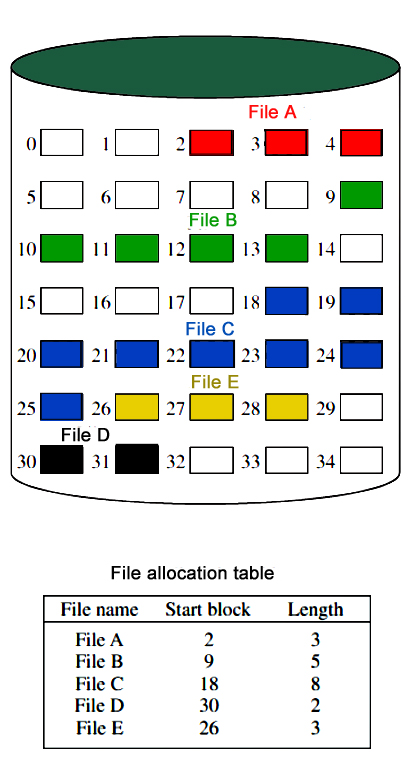
Disadvantages of Continuous Allocation
- External fragmentation will occur, making it difficult to find contiguous blocks of space of sufficient length. A compaction algorithm will be necessary to free up additional space on the disk.
- Also, with pre-allocation, it is necessary to declare the size of the file at the time of creation.
Linked Allocation(Non-Contiguous Allocation)
Allocation is on an individual block basis. Each block contains a pointer to the next block in the chain. Again the file table needs just a single entry for each file, showing the starting block and the length of the file. Although pre-allocation is possible, it is more common simply to allocate blocks as needed. Any free block can be added to the chain. The blocks need not be continuous. An increase in file size is always possible if a free disk block is available. There is no external fragmentation because only one block at a time is needed but there can be internal fragmentation but it exists only in the last disk block of the file.
Disadvantage Linked Allocation(Non-contiguous allocation)
- Internal fragmentation exists in the last disk block of the file.
- There is an overhead of maintaining the pointer in every disk block.
- If the pointer of any disk block is lost, the file will be truncated.
- It supports only the sequential access of files.
Indexed Allocation
It addresses many of the problems of contiguous and chained allocation. In this case, the file allocation table contains a separate one-level index for each file: The index has one entry for each block allocated to the file. The allocation may be on the basis of fixed-size blocks or variable-sized blocks. Allocation by blocks eliminates external fragmentation, whereas allocation by variable-size blocks improves locality. This allocation technique supports both sequential and direct access to the file and thus is the most popular form of file allocation.
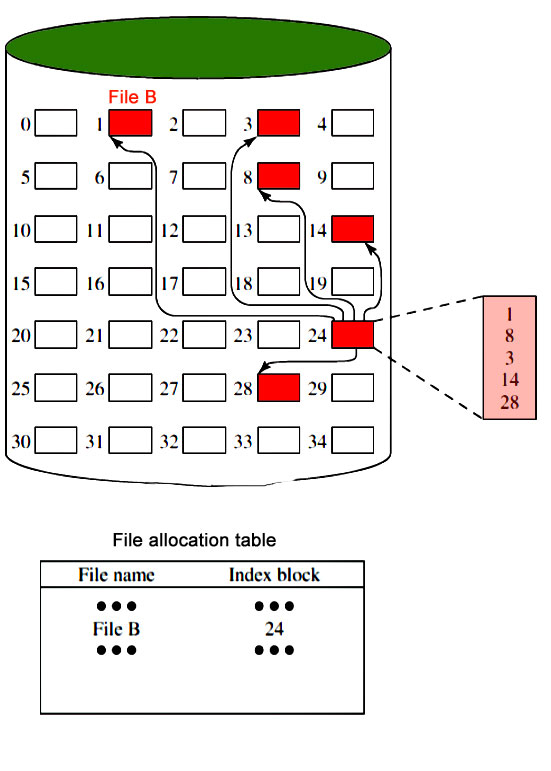
Disk Free Space Management
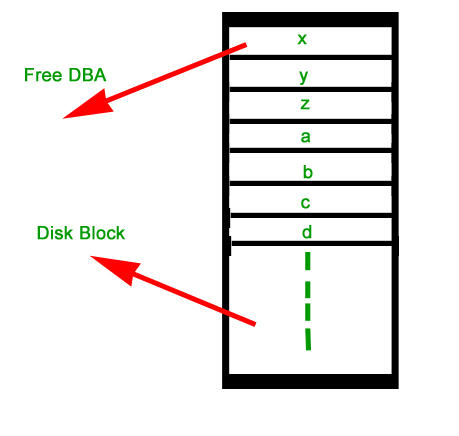
Just as the space that is allocated to files must be managed, so the space that is not currently allocated to any file must be managed. To perform any of the file allocation techniques, it is necessary to know what blocks on the disk are available. Thus we need a disk allocation table in addition to a file allocation table. The following are the approaches used for free space management.
- Bit Tables: This method uses a vector containing one bit for each block on the disk. Each entry for a 0 corresponds to a free block and each 1 corresponds to a block in use.
For example 00011010111100110001
In this vector every bit corresponds to a particular block and 0 implies that that particular block is free and 1 implies that the block is already occupied. A bit table has the advantage that it is relatively easy to find one or a contiguous group of free blocks. Thus, a bit table works well with any of the file allocation methods. Another advantage is that it is as small as possible.
- Free Block List: In this method, each block is assigned a number sequentially and the list of the numbers of all free blocks is maintained in a reserved block of the disk.
Advantages of File System
- Organization: A file system allows files to be organized into directories and subdirectories, making it easier to manage and locate files.
- Data protection: File systems often include features such as file and folder permissions, backup and restore, and error detection and correction, to protect data from loss or corruption.
- Improved performance: A well-designed file system can improve the performance of reading and writing data by organizing it efficiently on disk.
Disadvantages of File System
- Compatibility issues: Different file systems may not be compatible with each other, making it difficult to transfer data between different operating systems.
- Disk space overhead: File systems may use some disk space to store metadata and other overhead information, reducing the amount of space available for user data.
- Vulnerability: File systems can be vulnerable to data corruption, malware, and other security threats, which can compromise the stability and security of the system.
FAQs on File System
Q.1: How does a file system organize data?
Answer:
A file system organizes data by using a hierarchical structure consisting of directories (also called folders) and files. Directories can contain both files and subdirectories, forming a tree-like structure. This allows users to organize their files into meaningful groups and navigate through the file system using paths or directory structures.
Q.2: What is a file allocation table (FAT)?
Answer:
The File Allocation Table (FAT) is a file system structure used by some operating systems, including older versions of Windows. It uses a table to keep track of the allocation status of each cluster (a fixed-size block of storage) on the disk. The FAT file system has evolved over time, with variations such as FAT12, FAT16, and FAT32, supporting different disk sizes and features.
Q.3: What is NTFS (New Technology File System)?
Answer:
NTFS (New Technology File System) is a file system introduced by Microsoft with Windows NT. It is the default file system used by modern versions of Windows, including Windows XP, Windows 7, Windows 10, and Windows Server editions. NTFS offers features such as improved performance, reliability, security, support for large file sizes and volumes, file compression, encryption, and access control.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...