File caching enhances I/O performance because previously read files are kept in the main memory. Because the files are available locally, the network transfer is zeroed when requests for these files are repeated. Performance improvement of the file system is based on the locality of the file access pattern. Caching also helps in reliability and scalability.
File caching is an important feature of distributed file systems that helps to improve performance by reducing network traffic and minimizing disk access. In a distributed file system, files are stored across multiple servers or nodes, and file caching involves temporarily storing frequently accessed files in memory or on local disks to reduce the need for network access or disk access.
Here are some ways file caching is implemented in distributed file systems:
Client-side caching: In this approach, the client machine stores a local copy of frequently accessed files. When the file is requested, the client checks if the local copy is up-to-date and, if so, uses it instead of requesting the file from the server. This reduces network traffic and improves performance by reducing the need for network access.
Server-side caching: In this approach, the server stores frequently accessed files in memory or on local disks to reduce the need for disk access. When a file is requested, the server checks if it is in the cache and, if so, returns it without accessing the disk. This approach can also reduce network traffic by reducing the need to transfer files over the network.
Distributed caching: In this approach, the file cache is distributed across multiple servers or nodes. When a file is requested, the system checks if it is in the cache and, if so, returns it from the nearest server. This approach reduces network traffic by minimizing the need for data to be transferred across the network.
Advantages of file caching in distributed file systems include:
- Improved performance: By reducing network traffic and minimizing disk access, file caching can significantly improve the performance of distributed file systems.
- Reduced latency: File caching can reduce latency by allowing files to be accessed more quickly without the need for network access or disk access.
- Better resource utilization: File caching allows frequently accessed files to be stored in memory or on local disks, reducing the need for network or disk access and improving resource utilization.
However, there are also some disadvantages to file caching in distributed file systems, including:
- Increased complexity: File caching can add complexity to distributed file systems, requiring additional software and hardware to manage and maintain the cache.
- Cache consistency issues: Keeping the cache up-to-date can be a challenge, and inconsistencies between the cache and the actual file system can occur.
- Increased memory usage: File caching requires additional memory resources to store frequently accessed files, which can lead to increased
- memory usage on client machines and servers.
Overall, file caching is an important feature of distributed file systems that can improve performance and reduce latency. However, it also introduces some complexity and requires careful management to ensure cache consistency and efficient resource utilization.
The majority of today’s distributed file systems employ some form of caching. File caching schemes are determined by a number of criteria, including cached data granularity, cache size (large/ small/ fixed/ dynamic), replacement policy, cache location, modification propagation mechanisms, and cache validation.
Cache Location: The file might be kept in the disc or main memory of the client or the server in a client-server system with memory and disk.

Server’s Disk: It is always the original location where the file is saved. There is enough space here in case that file is modified and becomes longer. Additionally, the file is visible to all clients.
Advantages: There are no consistency issues because each file has only one copy. When a client wants to read a file, two transfers are required: from the server’s disk to the main memory, and from the client’s main memory to the server’s disk.
Disadvantages:
- It’s possible that both of these transfers will take some time. One part of the transfer time can be avoided by caching the file in the server’s main memory to boost performance.
- Because main memory is limited, an algorithm will be required to determine which files or parts of files should be maintained in the cache. This algorithm will be based on two factors: the cache unit and the replacement mechanism to apply when the cache is full.
Server’s Main Memory: The question is whether to cache the complete file or only the disk blocks when the file is cached in the server’s main memory. If the full file is cached, it can be stored in contiguous locations, and high-speed transmission results in a good performance. Disk block caching makes the cache and disc space more efficient.
Standard caching techniques are employed to overcome the latter issue. When compared to memory references, cache references are quite rare. The oldest block can be picked for eviction in LRU (Least Recently Used). The cache copy can be discarded if there is an up-to-date copy on the disk. The cache data can also be written to the disk. Clients can easily and transparently access a cached file in the server’s main memory. The server can easily keep disks and main memory copies of the file consistent. Only one copy of the file exists in the system, according to the client.
Client’s disk: The data can also be saved on the client’s hard drive. Although network transfer is reduced, in the event of a cache hit, the disk must be accessed. Because the changed data will be available in the event of data loss or a crash, this technique improves reliability. The information can then be recovered from the client’s hard drive.
Even if the client is disconnected from the server, the file can still be accessed. Because access to the disk may be handled locally, there is no need to contact the server, this enhances scalability and dependability.
Advantages:
- Reliability increased as data can be recovered in case of data loss.
- The client’s disk has a significantly larger storage capacity than the client’s primary memory. It is possible to cache more data, resulting in the highest cache-hit ratio. The majority of distributed file systems employ a file-level data transfer architecture, in which the entire file is cached.
- Scalability is increased as access to the disk can be handled locally.
Disadvantages:
- The sole drawback is that disc caching is incompatible with disk-less workstations. Every cache requires disk access, resulting in a considerable increase in the response time. It must be decided whether to cache in the server’s main memory or on the client’s disc.
- Although server caching eliminates the need for disk access, network transfer is still required. Caching data on the client-side is a solution for reducing network transfer time. Whether the system should use the client’s main memory or the disk, depends on whether the system needs to save space or improve performance.
- The access is slow if the disk has more space. The main memory of the server may be able to provide a file faster than the client’s disc. Caching can be done on the client’s disc if the file size is very high. The below figure shows the simplest way, i.e., avoid caching.

Client’s Main Memory: Once it is agreed that the files should be cached in the client’s memory, caching can take place in the user process’s address space, the kernel, or a cache manager as a user process.
The second alternative is to cache the files in the address space of each user process, as shown:
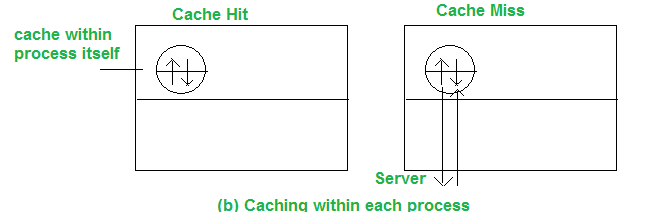
The system-call library is in charge of the cache. The files are opened, closed, read, and written during the process execution. The library saves the most frequently used files so that they can be re-used if necessary. The updated files are returned to the server once the operation has been completed. When individual processes open and close files regularly, this technique works well.
It’s fine for database managers, but not for programmers working in circumstances where the files might not be accessed again.
The file can be cached in the kernel instead of the user’s process address space, as shown. This technique, however, necessitates many systems calls to access the file for each cache hit.

A separate user-level cache manager can be used to cache the files. As a result, the kernel no longer has to maintain the file system code, and it becomes more isolated and flexible. The kernel can decide on the allocation of memory space for the program vs. cache on run time. The kernel can store some of the cached files in the disk if the cache manager runs in virtual memory, and the blocks are brought to the main memory on cache hit.

Advantages:
- This technique is more isolated and flexible (as the kernel no longer has to maintain the file system code)
- When individual processes open and close files regularly, the access time decreases. So, Gain in performance is maximum.
- Allows for diskless workstations.
- Contributes to the scalability and reliability of the system.
Disadvantages:
- A separate user-level cache manager is required.
- Client caching principles have no value with virtual memory, although the cache manager can lock some frequently requested pages.
Cache Consistency – Cache Update Policy:
When the cache is located on the client’s node, numerous users can access the same data or file at the same time in a file system. If all caches contain the same most current data, they are considered to be consistent. It’s possible that the data will become inconsistent if some users modify the file. The distributed system that uses a DFS must keep its data copies consistent.
Depending on when to propagate changes to the server and how to validate the authenticity of cache data, many consistency strategies are provided. Write-through, write-on-close, and centralized control are the three types.
When the cache is located on the client’s node & one user writes data to cache, it must also be visible to the other users as well. The written policy determines that when the writing is performed.
There are four cache update policies:
- Write-Through: When a new user edits a cache entry in this method, it is immediately written to the server. Any procedure that requires a file from the server will now always receive the most up-to-date information. Consider the following scenario: the client process reads the file, caches it, and then exits the process. Another client modifies the same file and sends the change to the server a short time later.
If a process is started on the first machine with the cached copy of the file, it will obtain an outdated copy. To avoid this, compare the time of modification of both copies, the cached copy on the client’s machine and the uploaded copy on the server, to validate the file with the server.
- Delayed Write: To reduce continuous network traffic, write all updates to the server periodically or batch them together. It’s known as ‘delayed-write.’ This method enhances performance by allowing for a single bulk write operation rather than several tiny writes. The temporary file is not stored on the file server in this case.
- Write on close: One step forward is to only write the file back to the server once it has been closed. ‘Write on close’ is the name of the algorithm. The second write overwrites the first if two cached files are written back to back. It’s comparable to what happens when two processes read or write in their own address space and then write back to the server in a single CPU system.
- Centralized Control: For tracking purposes, the client sends information about the files it has just opened to the server, which then performs read, write, or both activities. Multiple processes may read from the same file, but once one process has opened the file for writing, all other processes will be denied access. After the server receives notification that the file has been closed, it updates its table, and only then can additional users access the file.
Cache Validation Scheme:
When a cache’s data is modified, the modification propagation policy tells when the master copy of the file on the server node is updated. It provides no information about when the file data in other nodes’ caches are updated. Data from a file may be stored in the caches of many nodes at the same time.
When another client alters the data corresponding to the cache item in the master copy of the file on the server, the client’s cache entry becomes outdated. It’s required to check whether the data cached at a client node matches the master copy. If this is not the case, the cached data must be invalidated and a new version of the data must be requested from the server.
To check cache data’s Validity, 2 schemes are :
- Client-initiated Approach: The client connects to the server and verifies that the data it has in its cache is consistent with the master copy. The checking can be done at different times as-
- Verify before each access: As here the server must be called each time an access is made, this negates the actual purpose of caching data.
- Verifying periodically: Validation is done at a regular predetermined interval
- Verify the opening of the file: The cache entry is checked when a file is opened.
- Server-initiated Approach: When a client opens a file, it informs the file server of the purpose for opening the file – reading, writing, or both. It is then the duty of the file server to keep track of which client is working on which file and in which mode(s). When the server identifies any chance of inconsistency when the file is used by various clients, it reacts.
- A client notifies the server of the closure, as well as any changes made to the file when it closes a file. The server then updates its database to reflect which clients have which files open in which modes.
- The server can deny/queue the request, or disable caching by requesting that all clients who have the file open remove it from their caches whenever a new client requests to open a file that is already open and the server discovers any inconsistency which is there/may occur.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...