Euclidean geometry is the study of 2-Dimensional geometrical shapes and figures. Euclidean geometry is based on different axioms and theorems. The word geometry is derived from the Greek words ‘geo’ meaning Earth and ‘metrein’ meaning ‘To measure’. Thus, geometry is the measure of the Earth or various shapes present on the Earth.
Euclidean geometry as the name suggests was first used by the famous Greek mathematician Euclid. He described the geometry of flat objects in his book “Elements” and was the pioneer in this field. He gives various axioms or postulates that are obvious universal truths, (but they can not be proved by usual means). He stated 5 main axioms which are discussed below in the article. Let’s learn about them in detail in this article.
History of Euclid Geometry
Geometry is widely used in the History of mankind for various purposes, we found artefacts and sites that state that ancient humans have a very deep knowledge of geometry. In one of the earliest cities of the world such as in Harappa and Mohenjo-Daro historians have found that these cities are planned with proper drainage systems and other facilities. This proves that they have a deep understanding of Geometry. Also, one of the wonders of the world the Pyramid of Giza in Egypt, can not be built without the knowledge of Geometry.
The advancement in the field of geometry is traced back to the Greek philosopher and mathematician Euclid, that is credited with the first understanding of modern geometry. He was the first to formulate the concept of Geometry in his book “Elements”.
Who was Euclid?
Euclid, often referred to as the “Father of Geometry”, was an ancient Greek mathematician active around 300 BC1. He is best known for his treatise on geometry, the Elements, which established the foundations of geometry that largely dominated the field until the early 19th century.
Euclid’s work involved new innovations in combination with a synthesis of theories from earlier Greek mathematicians, including Eudoxus of Cnidus, Hippocrates of Chios, and Theaetetus1. With Archimedes and Apollonius of Perga, Euclid is generally considered among the greatest mathematicians of antiquity, and one of the most influential in the history of mathematics.
Very little is known of Euclid’s life, and most information comes from the scholars Proclus and Pappus of Alexandria many centuries later1. It is now generally accepted that he spent his career in Alexandria and lived around 300 BC1. In the Elements, Euclid deduced the theorems from a small set of axioms1. He also wrote works on perspective, conic sections, spherical geometry, number theory, and mathematical rigour.
What is Euclid’s Geometry?
These ancient civilizations used geometry mostly for practical purposes and there was little emphasis on the reasoning behind the statements. Euclid thought of geometry as an abstract model of the world. The idea of the point, lines, and shapes was derived from what was seen around in the real world. He studied real-world objects to formalize the concept of solid.
A solid has shape, size, and position and can be moved from one place to another. Its boundaries are called surfaces. They separate one part of space from another. They are assumed to have no thickness. The boundaries of surfaces are made up of curves or straight lines. These lines or curves are in turn made up of points.
From solid to the line, at each step, we lose one extension which is defined as dimension.
Euclid’s Definitions
Various definitions that are given by Euclid that are used in studying Euclid’s geometry are,
- A point is that which has no part.
- A line is breadthless.
- The ends of a line are points.
- A straight line is a line that lies evenly with the points on itself.
- A surface is that which has length and breadth only.
- The edges of a surface are lines.
- A plane surface is a surface that lies evenly with straight lines on it.
Examples of Euclidean Geometry
There are various examples of Euclidean geometry and some of the common examples of Euclidean Geometry include the geometry of,
Euclid defines angles as the inclination of one straight line on another. Similarly, a circle is defined as a plane figure in which all the points on the boundary are at a constant distance from the fixed point (center).
Non-Euclidean Geometry
All the geometrical figures that do not come under Euclidean Geometry are studied under Non-Euclidean Geometry. This is the branch of geometry that deals with 3-Dimensional figures, curves, planes, prism, etc. This branch of geometry commonly defines spherical geometry and hyperbolic geometry.
Euclidean and Non-Euclidean Geometry Differences
The basic differences between Euclidean and Non-Euclidean Geometry are that Euclidean Geometry deals with flat figures in 2-Dimension and Non-Euclidean Geometry deals with spherical geometry and hyperbolic geometry in 3D.
This difference can be understood with the help of an example of a parallel line.
In Euclidean Geometry there is only one line parallel to another line and passing through a fixed point, whereas in Non-Euclidean Geometry we can have multiple lines in 3-Dimensions which are at a constant distance from a line and passes through a line.
Theorems Proved by Euclid
Euclid’s proofs are outlined in his work “Elements“, where he established the foundation of geometry. While the exact methods may vary for each theorem, I’ll provide a brief overview of how Euclid likely proved each one:
- Congruence of Triangles: Euclid used the concept of corresponding parts of congruent triangles. By demonstrating that corresponding sides and angles of two triangles are equal, he showed that the triangles are congruent.
- Similarity of Triangles: Similarity is based on having equal corresponding angles and proportional sides. Euclid likely proved this theorem by showing that if two angles of one triangle are equal to two angles of another, then the third angles must also be equal, leading to similarity.
- Areas: Euclid’s approach to measuring areas involved decomposing shapes into simpler figures whose areas are known. By comparing these figures to a unit square, he established a method for measuring area.
- Pythagorean Theorem: Euclid might have proved the Pythagorean theorem using methods involving the area of squares constructed on the sides of a right triangle. By comparing the areas of these squares, he demonstrated the relationship among the triangle’s sides.
- Circles: Euclid used properties of angles formed by chords and radii within circles to establish relationships between equal chords and their corresponding angles.
- Regular Polygons: Euclid likely demonstrated that in regular polygons, all sides and angles are equal by dividing the polygon into congruent triangles and applying congruence principles.
- Conic Sections: While Euclid did not explicitly work on conic sections, his successors used similar geometric principles to study these curves. Conic sections arise from the intersection of a plane with a cone, and their properties can be derived using geometric constructions and proofs.
Euclid’s approach in “Elements” was deductive, building upon definitions, axioms, and previously proven propositions to establish new results. His proofs often relied on logical reasoning and geometric constructions, setting the standard for mathematical rigor for centuries to come.
Euclidean Geometry in Engineering
Euclidean geometry, as laid out by the ancient Greek mathematician Euclid, forms the basis of much of modern engineering, providing fundamental principles and tools for various applications across different engineering disciplines. Here’s how Euclidean geometry intersects with various aspects of engineering:
Design and Analysis
Stress Analysis: Engineers use Euclidean geometry principles to analyze the distribution of stress within structures and materials. Concepts such as centroids, moments of inertia, and beam bending are essential for stress analysis.
Gear Design: Euclidean geometry is employed to design gears, ensuring proper meshing and transmission of motion.
Heat Exchange Design: Geometry plays a crucial role in the design of heat exchangers, determining surface area, flow paths, and heat transfer rates.
Lens Design: Geometric optics principles are used in lens design to determine focal lengths, image formation, and aberration correction.
Dynamics
Vibration Analysis: Euclidean geometry is applied in the analysis of vibration modes and frequencies of mechanical systems, aiding in the design of structures and machinery to mitigate vibrations.
Wing Design: Aircraft wing design relies on geometric principles to optimize aerodynamic performance, including airfoil shapes, wing span, and wingtip geometry.
Satellite Orbits: Engineers use Euclidean geometry to model and analyze satellite orbits, predicting trajectories and ensuring proper positioning for communication, observation, and navigation satellites.
CAD Systems
3D Modeling: Computer-aided design (CAD) systems leverage Euclidean geometry to create accurate 3D models of mechanical components and systems, facilitating visualization and analysis.
Design and Manufacturing: Euclidean geometry is integral to CAD/CAM systems, aiding in the design and manufacturing of precision components through computer-controlled machining processes.
Evolution of Drafting Practices: Euclidean geometry forms the foundation of drafting practices, which have evolved from manual drafting to digital design using CAD systems.
Circuit Design
PCB Layouts: Euclidean geometry principles are applied in the layout and routing of printed circuit boards (PCBs), ensuring efficient placement of components and optimized signal paths.
Electromagnetic and Fluid Flow Field
Antenna Design: Engineers use Euclidean geometry and electromagnetic field theory to design antennas for communication, radar, and sensing applications.
Field Theory: Euclidean geometry underpins the mathematical models used to analyze electromagnetic fields, fluid flow patterns, and heat transfer phenomena in engineering systems.
Controls
Control System Analysis: Engineers apply Euclidean geometry and mathematical tools to analyze the behavior and stability of control systems, ensuring reliable and efficient operation.
Calculation Tools: Euclidean geometry is utilized in the development of calculation tools and software for control system design, simulation, and optimization.
Euclidean geometry serves as a foundational framework in engineering, providing essential principles and techniques for design, analysis, simulation, and optimization across a wide range of engineering disciplines. Its applications span from structural analysis and mechanical design to electromagnetics, fluid dynamics, and control systems.
Properties of Euclidean Geometry
Various properties of Euclidean Geometry are:
- Euclidean Geometry is the study of plane 2-Dimensional figures.
- Euclidean Geometry defines a point, a line, and a plane.
- It says that a solid has shape, size, and position, and it can be moved from one place to another.
- The sum of the interior angles of the triangle is 180 degrees.
- Parallel lines never intersect each other.
- The shortest distance between two lines is always the perpendicular distance between them.
Elements in Euclidean Geometry
Euclidean Geometry is the work done by the famous mathematician Euclid and is compiled in his book “Elements” consisting of 13 different elements. These Elements are collections of the various definitions, postulates (axioms), propositions (theorems and constructions), and mathematical proofs of these propositions.
Books 1st to 4th and 6th discuss plane geometrical figures, whereas his other books discuss the geometry of other figures. The work of Euclid laid the foundation of modern-day geometry.
For a better understanding of Geometry Euclid assumed some properties that need not be proven. All these assumptions are considered to be universal truths and they can be easily divided into two categories,
Postulates: Various Assumptions that are always true.
Axiom: Various Common Notions that are always true.
Euclid’s Axioms
Euclid’s Axioms which are used to study Euclidean Geometry are:
- Things which are equal to the same thing are equal to one another.
- If equals are added to equals, the wholes are equal.
- If equals are subtracted from equals, the remainders are equal.
- Things which coincide with one another are equal to one another.
- The whole is greater than the part.
- Things which are double of the same things are equal to one another.
- Things which are halves of the same things are equal to one another.
Euclid’s Postulates
Euclid has proposed five postulates that are widely used in geometry that are:
Euclid Postulate 1
A straight line may be drawn from any one point to any other point.
Notice that this postulate says that there is at least one straight line that passes through two points but says nothing about whether more than one line like this is possible. But in his work, Euclid has often assumed it to be unique.
Let’s write this result as an axiom.
Axiom: Given two distinct points, there is a unique line that passes through them.
This statement is self-evident, let’s see it through a figure.
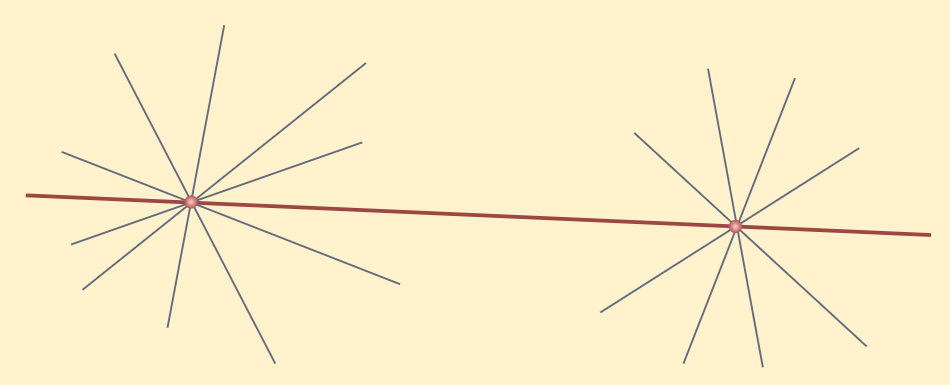
Euclid Postulate 1
Euclid Postulate 2
A terminated line can be produced indefinitely.
Euclid terms a line segment as a terminated line. We know that a line segment can be extended in any of the directions.
Euclid Postulate 3
A circle can be drawn with any center and any radius.
Euclid Postulate 4
All right angles are equal to one another.
Euclid Postulate 5
If a straight line falling on two straight lines makes the interior angles on the same side of it taken together less than two right angles, then the two straight lines, if produced indefinitely, meet on that side on which the sum of angles is less than two right angles.
For Example:
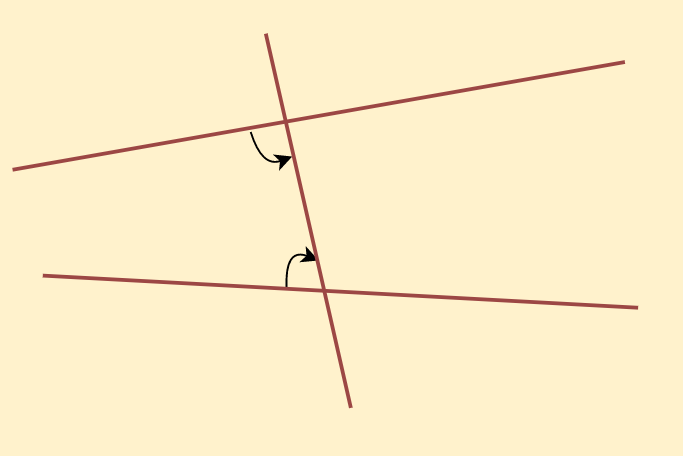
Euclid Postulate 5
We can see here, that the sum of interior angles is less than two right angles. Therefore, these two lines will intersect at a particular point if extended indefinitely.
Theorem: Two distinct lines cannot have more than one point in common.
Proof:
Assume two distinct lines “p” and “q”, now we have to prove they intersect at only one distinct point.
We prove this using the contradiction method. Suppose these two lines intersect at two distinct points, i.e. suppose they intersect at points A and B this can not be true as it violates various above Postulates thus, by contradiction, we can say that, Two distinct lines cannot have more than one point in common.
Hence Proved.
Examples of Euclidean Geometry
Example 1: On a straight lines AB, there exists a point C such that, AC = BC. Prove that the line AC is half of the line segment AB.
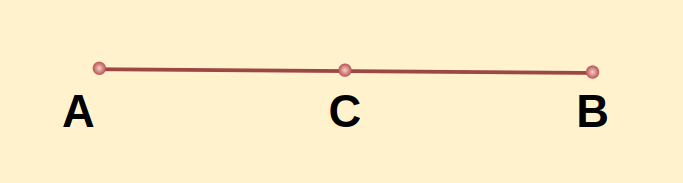
Solution:
Given: AC= BC
To Prove: AC= 1/2 AB
Proof:
We already know from the figure, AB=AC+ BC
But it is given that AC= BC
Therefore, we can write, AB= AC+ AC
AB= 2AC
AC= 1/2 AB
Hence proved.
Example 2: In the figure below, AD is a line segment, and B and C are two points lying on the line such that AC = BD, Prove that AB = CD.
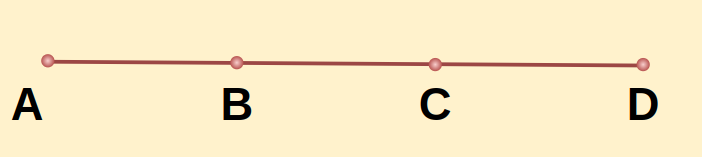
Solution:
Given: AC = BD
To Prove: AB = CD
Proof:
From the given figure, we can write, AC = AB + BC ⇢(1)
BD = BC + CD ⇢(2)
Equating equation (1) and (2) since, AC = BD (given)
AB + BC= BC + CD
AB = CD
Hence Proved.
Euclidean Geometry – FAQs
What is Euclidean Geometry?
The branch of geometry that studies flat shapes, figures, straight lines and others in 2-D is called Euclidean Geometry.
What is Difference between Euclidean and Non-Euclidean Geometry?
Euclidean geometry deals with figures or flat surfaces in two dimensions whereas non-Euclidean geometry is the opposite of Euclidean Geometry and it deals with all the shapes which do not come under Euclidean geometry i.e. spherical shapes, curves shapes and others.
What are the Five Postulates of Euclidean geometry?
The 5 postulates in Euclid’s Geometry are,
- A straight line may be drawn from any one point to any other point.
- A terminated line can be produced indefinitely.
- A circle can be drawn with any centre and any radius.
- All right angles are equal to one another.
- If a straight line falling on two straight lines makes the interior angles on the same side of it taken together less than two right angles, then the two straight lines, if produced indefinitely, meet on that side on which the sum of angles is less than two right angles.
What are the 7 Axioms of Euclids?
Axioms are common notions or theories made by Euclid in Euclid’s geometry. The 7 axioms of Euclid’s geometry are:
- Things which are equal to the same thing are equal to one another.
- If equals are added to equals, the wholes are equal.
- If equals are subtracted from equals, the remainders are equal.
- Things which coincide with one another are equal to one another.
- The whole is greater than the part.
- Things which are double the same things are equal to one another.
- Things which are halves of the same things are equal to one not
What is Meant by Non-Euclidean Geometry?
The branch of geometry that is completely opposite to Euclid’s geometry is called Non-Euclidean Geometry. In this branch of geometry, we study spherical geometry shapes and others.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...