Dual Support Vector Machine
Last Updated :
23 Jan, 2023
Pre-requisite: Separating Hyperplanes in SVM
The Lagrange multiplier equation for the support vector machine. The equation of that can be given by:
![\underset{\vec{w},b}{min} \underset{\vec{a}\geq 0}{max} \frac{1}{2}\left \| w \right \|^{2} - \sum_{j}a_j\left [ \left ( \vec{w} \cdot \vec{x}_{j} \right )y_j - 1 \right ]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-e3af7b114ae1c6d11097dcf8b453184d_l3.png "Rendered by QuickLaTeX.com")
Now, according to the duality principle, the above optimization problem can be viewed as both primal (minimizing over w and b) or dual (maximizing over a).
![\underset{\vec{a}\geq 0}{max}\underset{\vec{w},b}{min} \frac{1}{2}\left \| w \right \|^{2} - \sum_{j}a_j\left [ \left ( \vec{w} \cdot \vec{x}_{j} \right )y_j - 1 \right ]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-769d05932d6163e5915c127212c9b757_l3.png "Rendered by QuickLaTeX.com")
Slater condition for convex optimization guarantees that these two are equal problems.
To obtain minimum wrt w and b, the first-order partial derivative wrt these variables must be 0:

Now, put the above equation in the Lagrange multiplier equation and simplify it.

In the above equation, the term
 because, b is just a constant and the rest is from the above equation”
because, b is just a constant and the rest is from the above equation”

To find b, we can also use the above equation and constraint
 :
:

Now, the decision rule can be given by:

Notice, we can observe from the above rule that the Lagrange multiplier just depends upon the dot product of xi with unknown variable x. This dot product is defined as the kernel function, and it is represented by K

Now, for the linearly inseparable case, the dual equation becomes:

Here, we added a constant C, it is required because of the following reasons:
- It prevents the value of
 from
from  .
. - It also prevents the models from overfitting, meaning that some misclassification can be accepted.
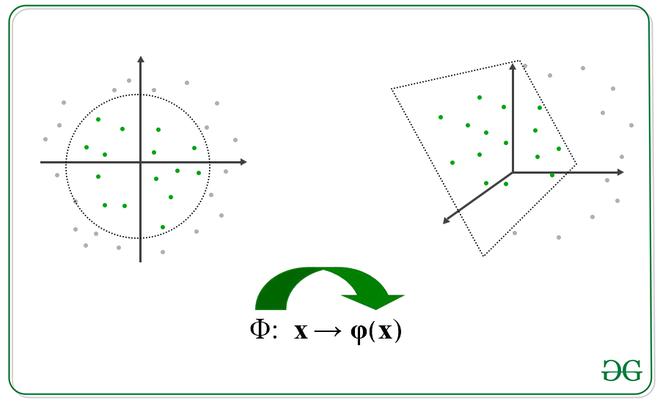
Image depicting transformation
we apply transformation into another space such that the following. Note, we don’t need to specifically calculate the transformation function, we just need to find the dot product of those to get kernel function, however, this transformation function can be easily established.

where,
 is the transformation function.
is the transformation function.
The intuition behind that many of time a data can be separated by a hyperplane in a higher dimension. Let’s look at this in more detail:
Suppose we have a dataset that contains only 1 independent and 1 dependent variable. The plot below represents the data:
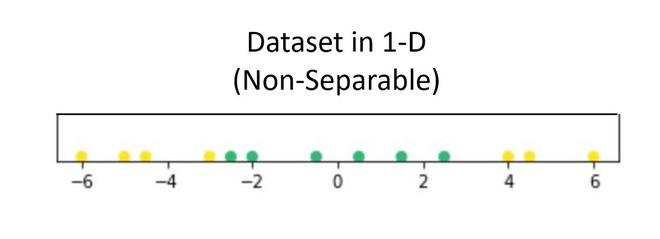
Now, in the above plot, it is difficult to separate a 1D-hyperplane (point) that clearly separates the data points of different classes. But when this transformed to 2d by using some transformation, it provides options for separating the classes.
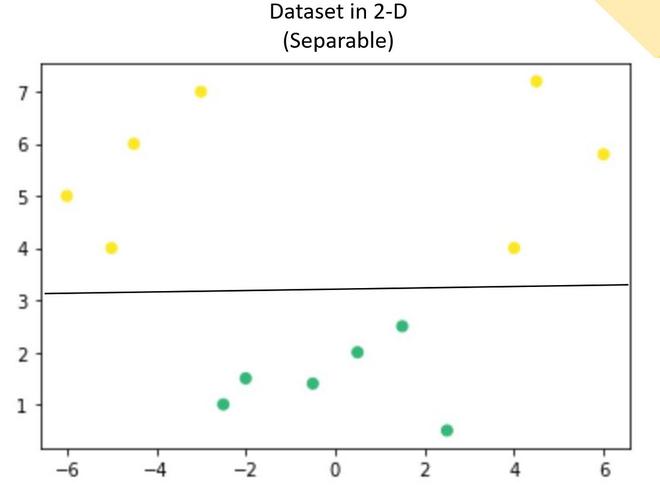
In the above example, we can see that an SVM line can clearly separate the two classes of the dataset.
There is some famous kernel that is used quite commonly:
- Polynomials with degree =n

- Polynomials with degree up to n


Implementation
Python3
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
cancer = datasets.load_breast_cancer()
X = cancer.data[:,:2]
Y = cancer.target
X.shape, Y.shape
h = .02
C=100
lin_svc = svm.LinearSVC(C=C)
svc = svm.SVC(kernel='linear', C=C)
rbf_svc = svm.SVC(kernel='rbf', gamma=0.7, C=C)
poly_svc = svm.SVC(kernel='poly', degree=3, C=C)
lin_svc.fit(X, Y)
svc.fit(X, Y)
rbf_svc.fit(X, Y)
poly_svc.fit(X, Y)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))
titles = ['linear kernel',
'LinearSVC (linear kernel)',
'RBF kernel',
'polynomial (degree 3) kernel']
plt.figure(figsize=(10,10))
for i, clf in enumerate((svc, lin_svc,rbf_svc, poly_svc )):
plt.subplot(2, 2, i + 1)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.set_cmap(plt.cm.flag_r)
plt.contourf(xx, yy, Z)
plt.scatter(X[:, 0], X[:, 1], c=Y)
plt.title(titles[i])
plt.show()
|
((569, 2), (569,))
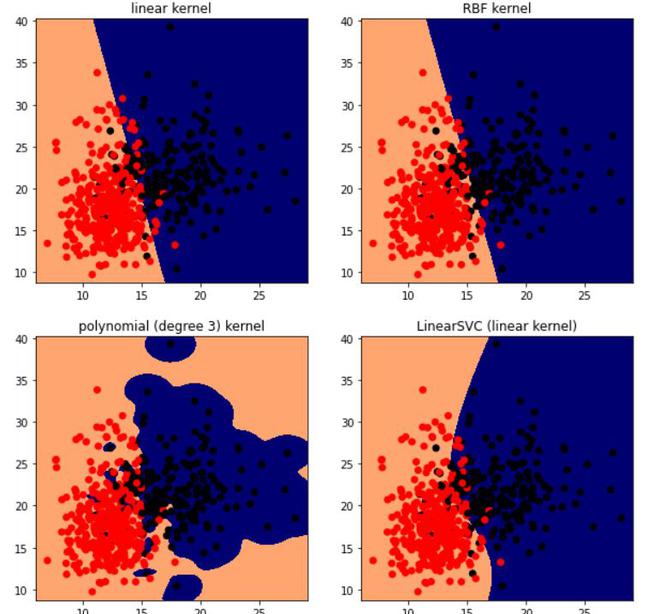
SVM using different kernels.
A Dual Support Vector Machine (DSVM) is a type of machine learning algorithm that is used for classification problems. It is a variation of the standard Support Vector Machine (SVM) algorithm that solves the optimization problem in a different way.
The main idea behind the DSVM is to use a technique called kernel trick which maps the input data into a higher-dimensional space, where it is more easily separable. The algorithm then finds the optimal hyperplane in this higher-dimensional space that maximally separates the different classes.
The dual form of the SVM optimization problem is typically used for large datasets because it is computationally less expensive than the primal form. The primal form of the SVM optimization problem is usually used for small datasets because it gives more interpretable results.
The DSVM algorithm has several advantages over other classification algorithms, such as:
-It is effective in high-dimensional spaces and with complex decision boundaries.
-It is memory efficient, as it only requires a subset of the training data to be used in the decision function.
-It is versatile, as it can be used with various types of kernels, such as linear, polynomial, or radial basis function kernels.
DSVM is mostly used in the fields of bioinformatics, computer vision, natural language processing, and speech recognition. It is also used in the classification of images, text, and audio data.
References:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...