Difference Between SSTF and C-LOOK Disk Scheduling Algorithm
Last Updated :
22 Feb, 2024
The secondary storage scheduling algorithm known as SSTF decides how the disk’s head and arm will move in response to read and write requests while in C-SCAN the head services request only in one direction(either left or right) until all the requests in this direction are not serviced and then jumps back to the farthest request in the other direction and services the remaining requests which gives a better uniform servicing as well as avoids wasting seek time for going till the end of the disk. You will discover the distinction between the SSTF and C-LOOK disk scheduling algorithms in this post. However, you must first understand the distinctions between the SSTF and C-LOOK disk scheduling algorithms.
SSTF Disk Scheduling Algorithm
SSTF stands for Shortest Seek Time First. As the name specifies, this algorithm serves the task request that is closest to the current position of the head or pointer. Here, the direction of the head plays a vital role in determining total head movement. If there occurs a tie between requests then the head will serve the request which encounters it, in its ongoing direction. Unlike C-LOOK, the SSTF algorithm is very efficient in total seek time.
Example – Consider a disk with 200 tracks (0-199) and the disk queue having I/O requests in the following order as follows:
98, 183, 40, 122, 10, 124, 65
The current head position of the Read\Write head is 53 and will move in the right direction. Calculate the total number of track movements of the Read/Write head using the SSTF algorithm.
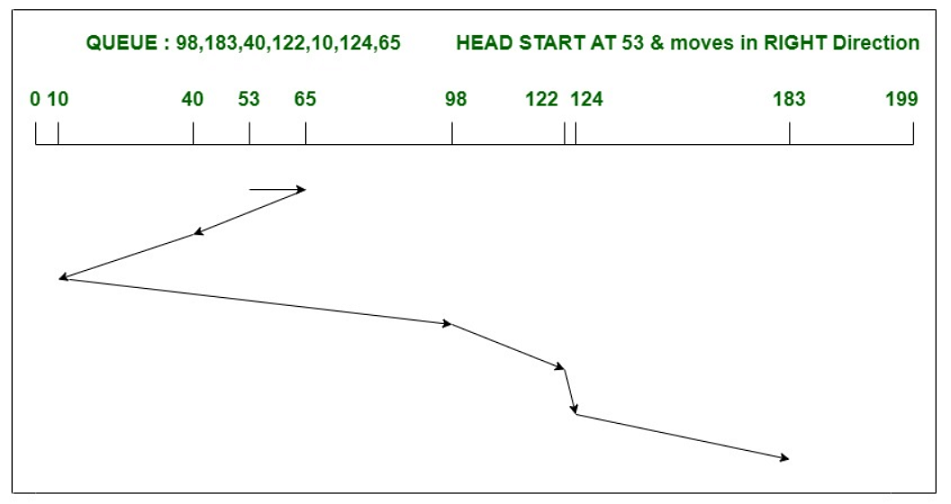
Total head movements = (65-53)+(65-40)+(40-10)+(98-10)+(122-98)+(124-122)+(183-124) = 240
Algorithm of SSTF
- Step 1: Let an array containing the indexes of the requested tracks be represented by the Request array. “head” refers to the disk head’s location.
- Step 2: Determine each track’s positive separation from the head in the request array.
- Step 3: Select a track with a minimal distance from the head from the specified array that hasn’t been accessed or serviced yet.
- Step 4: Using this distance, increase the total number of seeks.
- Step 5: The head position is now the currently serviced track position.
- Step 6: Repeat step 2 up until the request array’s last track is unserviced.
Advantages of SSTF
- It gets better and boosts throughput.
- The total search time of SSTF is less than that of FCFS.
- Both the average waiting time and response time are lower.
Disadvantages of SSTF
- Requests that are made distant from the head may result in starvation.
- Response and waiting times have a large degree of variety in the SSTF disk scheduling technique.
- Frequent direction changes of the head slow down the algorithm.
C-LOOK Disk Scheduling Algorithm
An improved variant of the SCAN and LOOK disk scheduling methods is the C-LOOK disk scheduling algorithm. The search time of this technique is faster than that of the C-SCAN algorithm, but it still uses the same concept of wrapping the tracks into a circular cylinder. As with C-SCAN, which we know is utilised to prevent starvation and provide more uniform service to all requests, C-LOOK does the same. In this algorithm, the head starts from first request in one direction and moves towards the last request at other end, serving all request in between. After reaching last request in one end, the head jumps in other direction and move towards the remaining requests and then satisfies them in same direction as before. Unlike SSTF, it doesn’t serves the task request which is closest to the current position of head or pointer.
Example –
Consider a disk with 200 tracks (0-199) and the disk queue having I/O requests in the following order as follows :
98, 183, 40, 122, 10, 124, 65
The current head position of the Read/Write head is 53 and will move in Right direction . Calculate the total number of track movements of Read/Write head using C-LOOK algorithm.
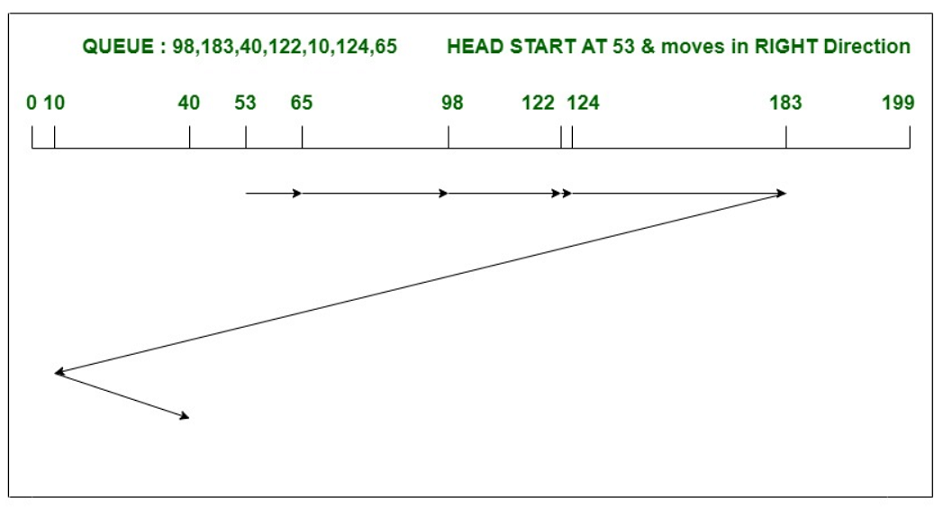
Total head movements = (65-53)+(98-65)+(122-98)
+(124-122)+(183-124)+(183-10)+(40-10)
= 333
Algorithm of C-LOOK
- Step 1: Assume that the head is the location of the disk head and that the Request array is an array that stores the indexes of the songs that have been requested in ascending order of arrival time.
- Step 2: The head moves in the same way as it did initially, and it continues in that direction.
- Step 3: The head responds to each request individually as it moves in that direction.
- Step 4: Until all requests in this direction have been fulfilled, the head keeps moving in the same direction.
- Step 5: Determine the exact separation between the tracks and the head while proceeding in this manner.
- Step 6: Using this distance, increase the total number of seeks.
- Step 7: The head position is now the currently serviced track position.
- Step 8: Repeat steps 5 through 8 until the final request is made in this manner.
- Step 9: Should we reach the final request in the current direction, we will turn around and move the head in that direction until we reach the final request that must be fulfilled in this direction, skipping the requests that come before it.
- Step 10: Change course and return to step 3 until no inquiries remain unanswered.
Advantages of C-LOOk
- Determine the disk head’s starting location.
- Arrange the disk requests that are still outstanding in the order that they will be addressed.
- As requests come in, handle them by scanning the disk in the selected direction.
- Return to the beginning of the disk and resume the operation as soon as the final request in the current direction has been fulfilled.
Disadvantages of C-LOOK
- When a lot of data needs to be read or written in one route, it might not be the best option because a lot of requests might get queued up in the other direction.
- It does not prioritise requests according to their urgency or relevance, therefore it might not be appropriate for real-time systems where quick response times are essential.
- Requests that are positioned far from the disk head’s current position may become starved as a result.
Difference Between SSTF and C-LOOK
| SSTF DISK SCHEDULING ALGORITHM |
C-LOOK DISK SCHEDULING ALGORITHM |
| SSTF algorithm can manipulate the requests in both directions. |
Whereas, C-LOOK algorithm services the requests only in one direction. |
| In SSTF algorithm there is an burden of finding closest request. |
Here, this algorithm causes more seek time as compared to SSTF. |
| SSTF algorithm lags in performance. |
But, the performance of C-LOOK is far better than SSTF. |
| In above example of SSTF algorithm, the head starts from 53 and analyse the request which is closest to it and hence moves in that direction. |
In above example of C-LOOK algorithm, the head moves from 53, serves all requests in right direction till it reaches the last request in one end. Then it jumps to the remaining requests and serve them in right direction only. |
| SSTF algorithm can leads to starvation. |
C-LOOK algorithm will never cause starvation to any requests. |
| SSTF provides high variance in average waiting time and response time. |
Whereas C-LOOK algorithm provides low variance in average waiting time and response time. |
Frequently Asked Question on SSTF and C-LOOK – FAQs
Which Disk Scheduling Algorithm has the best performance over all other Disk Scheduling Algorithms?
C-Look Disk Scheduling Algorithm has the best performance over all other Disk Scheduling Algorithms.
Why is SSTF not optimal?
There could be a risk of famine in SSTF. The SSTF algorithm is not the best one. Because we must determine the seek time in advance using this approach, there is a possibility of overhead in SSTF disk scheduling.Advantages
Is SSTF preemptive?
Because it is a non-preemptive CPU scheduling algorithm, once a process is assigned to a CPU, the CPU won’t be released until the process has finished running.
Can disk scheduling suffer from starvation due to the SSTF algorithm?
Finding the closest request has an overhead in the SSTF disk scheduling method. There is an overhead for locating end requests in this approach. The request that is farthest from the head in the SSTF disk scheduling algorithm will starve.
Share your thoughts in the comments
Please Login to comment...