Difference between Hierarchical and Network Data Model
Last Updated :
22 Aug, 2022
1. Hierarchical Data Model:
Hierarchical data model is the oldest type of the data model. It was developed by IBM in 1968. It organizes data in the tree-like structure. Hierarchical model consists of the following :
- It contains nodes which are connected by branches.
- The topmost node is called the root node.
- If there are multiple nodes appear at the top level, then these can be called as root segments.
- Each node has exactly one parent.
- One parent may have many child.
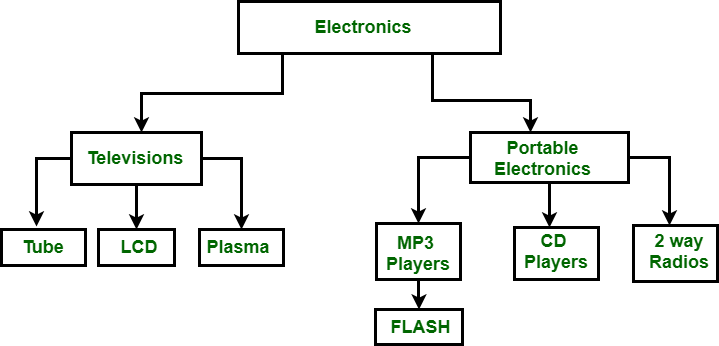
In the above figure, Electronics is the root node which has two children i.e. Televisions and Portable Electronics. These two has further children for which they act as parent. For example: Television has children as Tube, LCD and Plasma, for these three Television act as parent. It follows one to many relationship.
2. Network Data Model:
It is the advance version of the hierarchical data model. To organize data it uses directed graphs instead of the tree-structure. In this child can have more than one parent. It uses the concept of the two data structures i.e. Records and Sets.
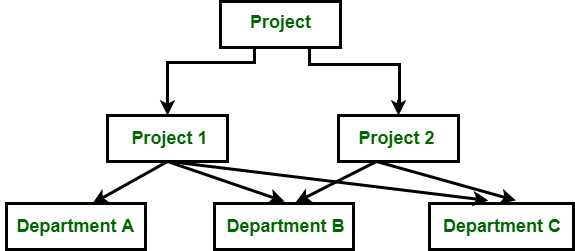
In the above figure, Project is the root node which has two children i.e. Project 1 and Project 2. Project 1 has 3 children and Project 2 has 2 children. Total there are 5 children i.e Department A, Department B and Department C, they are network related children as we said that this model can have more than one parent. So, for the Department B and Department C have two parents i.e. Project 1 and Project 2.
Difference between Hierarchical Data Model and Network Data Model :
| S. No. |
Hierarchical Data Model |
Network Data Model |
| 1. |
In this model, to store data hierarchy method is used. |
In this model, you could create a network that shows how data is related to each other. |
| 2. |
It implements 1:1 and 1:n relations. |
It implements 1:1, 1:n and also many to many relations. |
| 3. |
To organize records, it uses tree structure. |
To organize records, it uses graphs. |
| 4. |
Records are linked with the help of pointers. |
Records are linked with the help of linked list. |
| 5. |
Insertion anomaly exits in this model i.e. child node cannot be inserted without the parent node. |
There is no insertion anomaly. |
| 6. |
Deletion anomaly exists in this model i.e. it is difficult to delete the parent node. |
There is no deletion anomaly. |
| 7. |
It is used to access the data which is complex and asymmetric. |
It is used to access the data which is complex and symmetric. |
| 8. |
When update operation is performed, it suffers from inconsistency problem because of the existence of multiple instances of child records. |
No such problem exists because of the single occurrence of records while updating. |
| 9. |
This model lacks data independence. |
There is partial data independence in this model. |
| 10. |
Less flexible in comparison to the relational model. |
It is flexible. |
| 11. |
When you are searching for a record then firstly you need to visit parent record before retrieving a child record. |
Searching for a record is easy because of the availability of multiple access paths to reach data item. |
| 12. |
Example- IBM’s IMS (Information Management System) implement this model. |
Example- Oracle. SQL Server, Sybase DBMS implement this model.
|
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...