Difference between Data Cleaning and Data Processing
Last Updated :
07 May, 2023
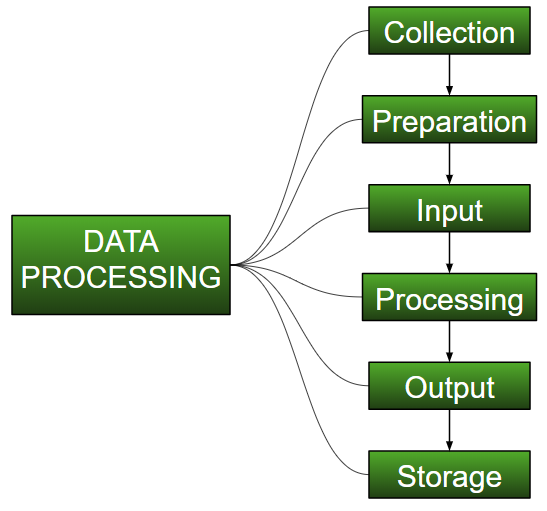
Data Processing: It is defined as Collection, manipulation, and processing of collected data for the required use. It is a task of converting data from a given form to a much more usable and desired form i.e. making it more meaningful and informative. Using Machine Learning algorithms, mathematical modelling and statistical knowledge, this entire process can be automated. This might seem to be simple but when it comes to really big organizations like Twitter, Facebook, Administrative bodies like Parliament, UNESCO and health sector organisations, this entire process needs to be performed in a very structured manner. So, the steps to perform are as follows:
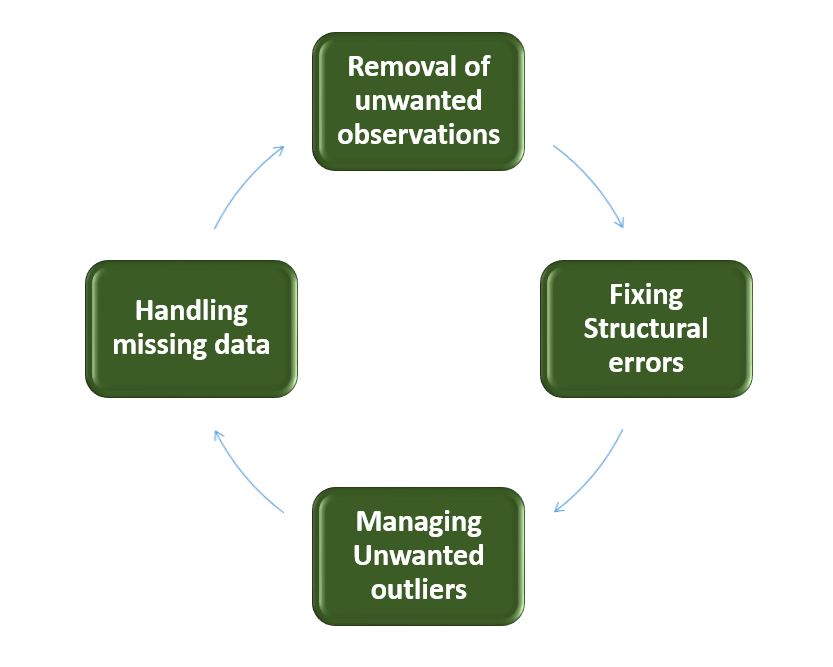
Data Cleaning: Data cleaning is the process of fixing or removing incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data within a dataset. It is one of the important parts of machine learning. It plays a significant part in building a model. Data Cleaning is one of those things that everyone does but no one really talks about. It surely isn’t the fanciest part of machine learning and at the same time, there aren’t any hidden tricks or secrets to uncover. However, proper data cleaning can make or break your project. Steps involved in Data Cleaning –
Data Processing Vs Data Cleaning
| Sr. no. |
Data Processing
|
Data Cleaning
|
| 1 |
Data Processing is done after data cleaning |
Data Cleaning is done before data Processing |
| 2 |
Data Processing requires necessary storage hardware like Ram, Graphical Processing units etc for processing the data |
Data Cleaning doesn’t require hardware tools. |
| 3 |
Data Processing Frameworks like Hadoop, Pig Frameworks etc |
Data Cleaning involves Removing Noisy data etc. No special Frameworks are used. |
| 4 |
Data Processing is difficult when compared to data cleaning. |
Data Cleaning is easier than data Processing. |
| 5 |
Examples:
- Loading Student data in Hadoop Cluster(data storage) and retrieving (processing)the marks less than 60 percent.
- Percentage calculation.
|
Examples:
- Finding the fraud data like age of the student is greater than the range and Percentage is not more than 100.
- Check whether the marks is not inserted or not. If not, we can verify and place the correct data in place of missed data.
|
| 6 |
Transforming and manipulating the data to extract insights and build models. |
Identifying and correcting errors, inconsistencies, and inaccuracies in the data to improve its quality and usability. |
| 7 |
Second step, performed after data cleaning. |
First step, performed before data processing. |
| 8 |
Statistical analysis, machine learning algorithms, visualization |
Handling missing data, handling outliers, data transformation, data integration, data validation and verification, data formatting. |
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...