Delete duplicates in a Pandas Dataframe based on two columns
Last Updated :
21 Mar, 2024
A dataframe is a two-dimensional, size-mutable tabular data structure with labeled axes (rows and columns). It can contain duplicate entries and to delete them there are several ways.
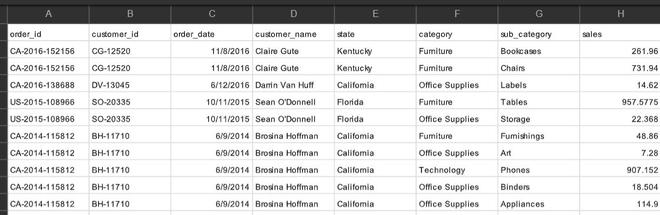
The dataframe contains duplicate values in column order_id and customer_id. Below are the methods to remove duplicate values from a dataframe based on two columns.
Method 1: using drop_duplicates()
Approach:
- We will drop duplicate columns based on two columns
- Let those columns be ‘order_id’ and ‘customer_id’
- Keep the latest entry only
- Reset the index of dataframe
Below is the python code for the above approach.
Python3
import pandas as pd
df1 = pd.read_csv("super.csv")
newdf = df1.drop_duplicates(
subset = ['order_id', 'customer_id'],
keep = 'last').reset_index(drop = True)
display(newdf)
|
Output:
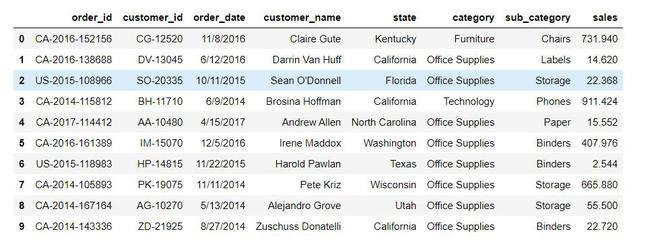
Method 2: using groupby()
Approach:
- We will group rows based on two columns
- Let those columns be ‘order_id’ and ‘customer_id’
- Keep the first entry only
The python code for the above approach is given below.
Python3
import pandas as pd
df1 = pd.read_csv("super.csv")
newdf1 = df1.groupby(['order_id', 'customer_id']).first()
print(newdf1)
|
Output:
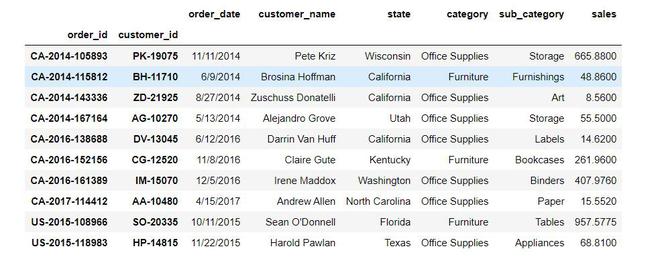
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...