Decision Tree Classifiers in Julia
Last Updated :
04 Apr, 2023
In statistics in Julia, classification is the problem of identifying to which of a set of categories (sub-populations) a new observation belongs, on the basis of a training set of data containing observations (or instances) whose category membership is known.
In the terminology of machine learning, classification is considered an instance of supervised learning, i.e., learning where a training set of correctly identified observations is available.
Some of the classification techniques which we have are:
- Linear Classifiers: Logistic Regression, Naive Bayes Classifier
- Nearest Neighbor
- Support Vector Machines
- Decision Trees
- Boosted Trees
- Random Forest
- Neural Networks
Decision tree classifiers
A Decision Tree is a simple representation of classifying examples. It is a Supervised Machine Learning where the data is continuously split according to a certain parameter.
Decision trees are commonly used in operations research and operations management. If in practice, decisions have to be taken online with no recall under incomplete knowledge, a decision tree should be paralleled by a probability model as the best choice model or online selection model algorithm. Another use of decision trees is as a descriptive means for calculating conditional probabilities.
A decision tree has mainly three components:
- Root Nodes: It represents the entire population or sample and this further gets divided into two or more homogeneous sets.
- Edges/Branch: Represents a decision rule and connect to the next node.
- Leaf nodes: Leaf nodes are the nodes of the tree that have no additional nodes coming off them. They don’t split the data any further
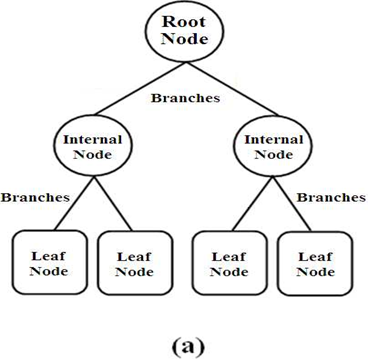
Implementation of Decision Tree Classifiers in Julia
Decision Tree is a flow chart like structure
- use axis-aligned linear decision boundaries to partition or bisect data
- Divide and conquer approach
Packages and Requirements
- Pkg.add(“DecisionTree”)
- Pkg.add(“DataFrames”)
- Pkg.add(“Gadfly”)
Julia
using DataFrames
using DecisionTree
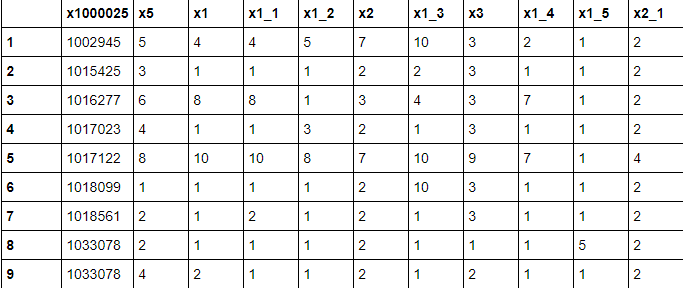
df = readtable("breastc.csv")
|
Output:
Julia
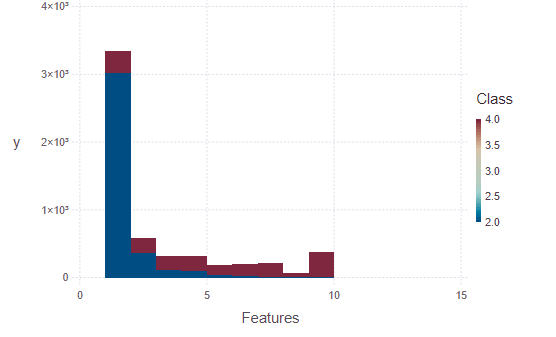
using Gadfly
plot(df, x = Xfeatures,
y = Ylabel, Geom.histogram,
color = :Class,
Guide.xlabel("Features"))
|
Output:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...