Data Science Process
Last Updated :
25 Sep, 2023
If you are in a technical domain or a student with a technical background then you must have heard about Data Science from some source certainly. This is one of the booming fields in today’s tech market. And this will keep going on as the upcoming world is becoming more and more digital day by day. And the data certainly hold the capacity to create a new future. In this article, we will learn about Data Science and the process which is included in this.
What is Data Science?
Data can be proved to be very fruitful if we know how to manipulate it to get hidden patterns from them. This logic behind the data or the process behind the manipulation is what is known as Data Science. From formulating the problem statement and collection of data to extracting the required results from them the Data Science process and the professional who ensures that the whole process is going smoothly or not is known as the Data Scientist. But there are other job roles as well in this domain as well like:
- Data Engineers
- Data Analysts
- Data Architect
- Machine Learning Engineer
- Deep Learning Engineer
Data Science Process Life Cycle
There are some steps that are necessary for any of the tasks that are being done in the field of data science to derive any fruitful results from the data at hand.
- Data Collection – After formulating any problem statement the main task is to calculate data that can help us in our analysis and manipulation. Sometimes data is collected by performing some kind of survey and there are times when it is done by performing scrapping.
- Data Cleaning – Most of the real-world data is not structured and requires cleaning and conversion into structured data before it can be used for any analysis or modeling.
- Exploratory Data Analysis – This is the step in which we try to find the hidden patterns in the data at hand. Also, we try to analyze different factors which affect the target variable and the extent to which it does so. How the independent features are related to each other and what can be done to achieve the desired results all these answers can be extracted from this process as well. This also gives us a direction in which we should work to get started with the modeling process.
- Model Building – Different types of machine learning algorithms as well as techniques have been developed which can easily identify complex patterns in the data which will be a very tedious task to be done by a human.
- Model Deployment – After a model is developed and gives better results on the holdout or the real-world dataset then we deploy it and monitor its performance. This is the main part where we use our learning from the data to be applied in real-world applications and use cases.
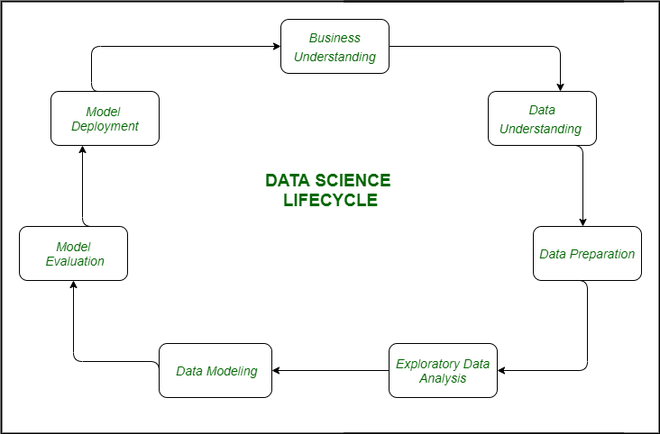
Data Science Process Life Cycle
Components of Data Science Process
Data Science is a very vast field and to get the best out of the data at hand one has to apply multiple methodologies and use different tools to make sure the integrity of the data remains intact throughout the process keeping data privacy in mind. Machine Learning and Data analysis is the part where we focus on the results which can be extracted from the data at hand. But Data engineering is the part in which the main task is to ensure that the data is managed properly and proper data pipelines are created for smooth data flow. If we try to point out the main components of Data Science then it would be:
- Data Analysis – There are times when there is no need to apply advanced deep learning and complex methods to the data at hand to derive some patterns from it. Due to this before moving on to the modeling part, we first perform an exploratory data analysis to get a basic idea of the data and patterns which are available in it this gives us a direction to work on if we want to apply some complex analysis methods on our data.
- Statistics – It is a natural phenomenon that many real-life datasets follow a normal distribution. And when we already know that a particular dataset follows some known distribution then most of its properties can be analyzed at once. Also, descriptive statistics and correlation and covariances between two features of the dataset help us get a better understanding of how one factor is related to the other in our dataset.
- Data Engineering – When we deal with a large amount of data then we have to make sure that the data is kept safe from any online threats also it is easy to retrieve and make changes in the data as well. To ensure that the data is used efficiently Data Engineers play a crucial role.
- Advanced Computing
- Machine Learning – Machine Learning has opened new horizons which had helped us to build different advanced applications and methodologies so, that the machines become more efficient and provide a personalized experience to each individual and perform tasks in a snap of the hand earlier which requires heavy human labor and time intense.
- Deep Learning – This is also a part of Artificial Intelligence and Machine Learning but it is a bit more advanced than machine learning itself. High computing power and a huge corpus of data have led to the emergence of this field in data science.
Knowledge and Skills for Data Science Professionals
As a Data Scientist, you’ll be responsible for jobs that span three domains of skills.
- Statistical/mathematical reasoning
- Business communication/leadership
- Programming
1. Statistics: Wikipedia defines it as the study of the collection, analysis, interpretation, presentation, and organization of data. Therefore, it shouldn’t be a surprise that data scientists need to know statistics.
2. Programming Language R/ Python: Python and R are one of the most widely used languages by Data Scientists. The primary reason is the number of packages available for Numeric and Scientific computing.
3. Data Extraction, Transformation, and Loading: Suppose we have multiple data sources like MySQL DB, MongoDB, Google Analytics. You have to Extract data from such sources, and then transform it for storing in a proper format or structure for the purposes of querying and analysis. Finally, you have to load the data in the Data Warehouse, where you will analyze the data. So, for people from ETL (Extract Transform and Load) background Data Science can be a good career option.
Steps for Data Science Processes:
Step 1: Defining research goals and creating a project charter
- Spend time understanding the goals and context of your research.Continue asking questions and devising examples until you grasp the exact business expectations, identify how your project fits in the bigger picture, appreciate how your research is going to change the business, and understand how they’ll use your results.
Create a project charter
A project charter requires teamwork, and your input covers at least the following:
- A clear research goal
- The project mission and context
- How you’re going to perform your analysis
- What resources you expect to use
- Proof that it’s an achievable project, or proof of concepts
- Deliverables and a measure of success
- A timeline
Step 2: Retrieving Data
Start with data stored within the company
- Finding data even within your own company can sometimes be a challenge.
- This data can be stored in official data repositories such as databases, data marts, data warehouses, and data lakes maintained by a team of IT professionals.
- Getting access to the data may take time and involve company policies.
Step 3: Cleansing, integrating, and transforming data-
Cleaning:
- Data cleansing is a subprocess of the data science process that focuses on removing errors in your data so your data becomes a true and consistent representation of the processes it originates from.
- The first type is the interpretation error, such as incorrect use of terminologies, like saying that a person’s age is greater than 300 years.
- The second type of error points to inconsistencies between data sources or against your company’s standardized values. An example of this class of errors is putting “Female” in one table and “F” in another when they represent the same thing: that the person is female.
Integrating:
- Combining Data from different Data Sources.
- Your data comes from several different places, and in this sub step we focus on integrating these different sources.
- You can perform two operations to combine information from different data sets. The first operation is joining and the second operation is appending or stacking.
Joining Tables:
- Joining tables allows you to combine the information of one observation found in one table with the information that you find in another table.
Appending Tables:
- Appending or stacking tables is effectively adding observations from one table to another table.
Transforming Data
- Certain models require their data to be in a certain shape.
Reducing the Number of Variables
- Sometimes you have too many variables and need to reduce the number because they don’t add new information to the model.
- Having too many variables in your model makes the model difficult to handle, and certain techniques don’t perform well when you overload them with too many input variables.
- Dummy variables can only take two values: true(1) or false(0). They’re used to indicate the absence of a categorical effect that may explain the observation.
Step 4: Exploratory Data Analysis
- During exploratory data analysis you take a deep dive into the data.
- Information becomes much easier to grasp when shown in a picture, therefore you mainly use graphical techniques to gain an understanding of your data and the interactions between variables.
- Bar Plot, Line Plot, Scatter Plot ,Multiple Plots , Pareto Diagram , Link and Brush Diagram ,Histogram , Box and Whisker Plot .
Step 5: Build the Models
- Build the models are the next step, with the goal of making better predictions, classifying objects, or gaining an understanding of the system that are required for modeling.
Step 6: Presenting findings and building applications on top of them –
- The last stage of the data science process is where your soft skills will be most useful, and yes, they’re extremely important.
- Presenting your results to the stakeholders and industrializing your analysis process for repetitive reuse and integration with other tools.
Benefits and uses of data science and big data
- Governmental organizations are also aware of data’s value. A data scientist in a governmental organization gets to work on diverse projects such as detecting fraud and other criminal activity or optimizing project funding.
- Nongovernmental organizations (NGOs) are also no strangers to using data. They use it to raise money and defend their causes. The World Wildlife Fund (WWF), for instance, employs data scientists to increase the effectiveness of their fundraising efforts.
- Universities use data science in their research but also to enhance the study experience of their students. • Ex: MOOC’s- Massive open online courses.
Tools for Data Science Process
As time has passed tools to perform different tasks in Data Science have evolved to a great extent. Different software like Matlab and Power BI, and programming Languages like Python and R Programming Language provides many utility features which help us to complete most of the most complex task within a very limited time and efficiently. Some of the tools which are very popular in this domain of Data Science are shown in the below image.

Tools for Data Science Process
Usage of Data Science Process
The Data Science Process is a systematic approach to solving data-related problems and consists of the following steps:
- Problem Definition: Clearly defining the problem and identifying the goal of the analysis.
- Data Collection: Gathering and acquiring data from various sources, including data cleaning and preparation.
- Data Exploration: Exploring the data to gain insights and identify trends, patterns, and relationships.
- Data Modeling: Building mathematical models and algorithms to solve problems and make predictions.
- Evaluation: Evaluating the model’s performance and accuracy using appropriate metrics.
- Deployment: Deploying the model in a production environment to make predictions or automate decision-making processes.
- Monitoring and Maintenance: Monitoring the model’s performance over time and making updates as needed to improve accuracy.
Issues of Data Science Process
- Data Quality and Availability: Data quality can affect the accuracy of the models developed and therefore, it is important to ensure that the data is accurate, complete, and consistent. Data availability can also be an issue, as the data required for analysis may not be readily available or accessible.
- Bias in Data and Algorithms: Bias can exist in data due to sampling techniques, measurement errors, or imbalanced datasets, which can affect the accuracy of models. Algorithms can also perpetuate existing societal biases, leading to unfair or discriminatory outcomes.
- Model Overfitting and Underfitting: Overfitting occurs when a model is too complex and fits the training data too well, but fails to generalize to new data. On the other hand, underfitting occurs when a model is too simple and is not able to capture the underlying relationships in the data.
- Model Interpretability: Complex models can be difficult to interpret and understand, making it challenging to explain the model’s decisions and decisions. This can be an issue when it comes to making business decisions or gaining stakeholder buy-in.
- Privacy and Ethical Considerations: Data science often involves the collection and analysis of sensitive personal information, leading to privacy and ethical concerns. It is important to consider privacy implications and ensure that data is used in a responsible and ethical manner.
- Technical Challenges: Technical challenges can arise during the data science process such as data storage and processing, algorithm selection, and computational scalability.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...