Creating a sqlite database from CSV with Python
Last Updated :
26 Dec, 2020
Prerequisites:
SQLite is a software library that implements a lightweight relational database management system. It does not require a server to operate unlike other RDBMS such as PostgreSQL, MySQL, Oracle, etc. and applications directly interact with a SQLite database. SQLite is often used for small applications, particularly in embedded systems and mobile applications. To interact with a SQLite database in Python, the sqlite3 module is required.
Approach
- Import module
- Create a database and establish connection-
To establish a connection, we use the sqlite3.connect() function which returns a connection object. Pass the name of the database to be created inside this function. The complete state of a SQLite database is stored in a file with .db extension. If the path is not specified then the new database is created in the current working directory.
Syntax:
sqlite3.connect(‘database_name.db’)
- Import csv using read_csv()
Syntax:
pandas.read_csv(‘file_name.csv’)
- Write the contents to a new table-
The function to_sql() creates a new table from records of the dataframe. Pass the table name and connection object inside this function. The column names of the table are same as the header of the CSV file. By default, the dataframe index is written as a column. Simply toggle the index parameter to False in order to remove this column. Additionally, the if_exists parameter specifies the behavior in case the table name is already being used. It can either raise error (fail), append new values or replace the existing table.
pandas.DataFrame.to_sql(table_name, connection_object, if_exists, index)
- Check the table contents-
Create a cursor object and execute the standard SELECT statement to fetch the contents of the newly created table.
Csv file in use: stud_data.csv
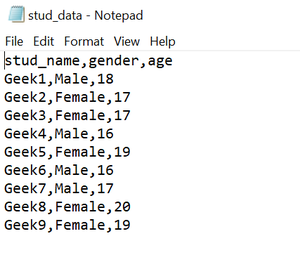
Program:
Python3
import sqlite3
import pandas as pd
conn = sqlite3.connect(r'C:\User\SQLite\University.db')
stud_data = pd.read_csv('stud_data.csv')
stud_data.to_sql('student', conn, if_exists='replace', index=False)
cur = conn.cursor()
for row in cur.execute('SELECT * FROM student'):
print(row)
conn.close()
|
Output:

Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...