Create PySpark DataFrame from list of tuples
Last Updated :
30 May, 2021
In this article, we are going to discuss the creation of a Pyspark dataframe from a list of tuples.
To do this, we will use the createDataFrame() method from pyspark. This method creates a dataframe from RDD, list or Pandas Dataframe. Here data will be the list of tuples and columns will be a list of column names.
Syntax:
dataframe = spark.createDataFrame(data, columns)
Example 1:
Python3
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
data = [("sravan", "IT", 80),
("jyothika", "CSE", 85),
("harsha", "ECE", 60),
("thanmai", "IT", 65),
("durga", "IT", 91)]
columns = ["Name", "Branch", "Percentage"]
dataframe = spark.createDataFrame(data, columns)
dataframe.show()
|
Output:
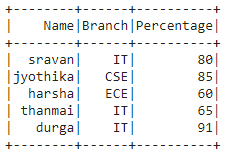
Example 2:
Python3
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
data = [("mango", "AP", "Guntur"),
("mango", "AP", "Chittor"),
("sugar cane", "AP", "amaravathi"),
("paddy", "TS", "adilabad"),
("wheat", "AP", "nellore")]
columns = ["Crop Name", "State", "District"]
dataframe = spark.createDataFrame(data, columns)
dataframe.show()
|
Output:

Example 3:
Python code to count the records (tuples) in the list
Python3
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
data = [("mango", "AP", "Guntur"),
("mango", "AP", "Chittor"),
("sugar cane", "AP", "amaravathi"),
("paddy", "TS", "adilabad"),
("wheat", "AP", "nellore")]
columns = ["Crop Name", "State", "District"]
dataframe = spark.createDataFrame(data, columns)
dataframe.count()
|
Output:
5
Share your thoughts in the comments
Please Login to comment...