Convert PySpark DataFrame to Dictionary in Python
Last Updated :
17 Jun, 2021
In this article, we are going to see how to convert the PySpark data frame to the dictionary, where keys are column names and values are column values.
Before starting, we will create a sample Dataframe:
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('DF_to_dict').getOrCreate()
data = [(('Ram'), '1991-04-01', 'M', 3000),
(('Mike'), '2000-05-19', 'M', 4000),
(('Rohini'), '1978-09-05', 'M', 4000),
(('Maria'), '1967-12-01', 'F', 4000),
(('Jenis'), '1980-02-17', 'F', 1200)]
columns = ["Name", "DOB", "Gender", "salary"]
df = spark.createDataFrame(data=data,
schema=columns)
df.show()
|
Output :
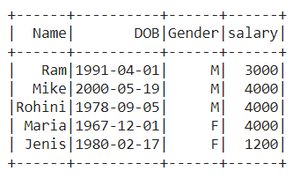
Method 1: Using df.toPandas()
Convert the PySpark data frame to Pandas data frame using df.toPandas().
Syntax: DataFrame.toPandas()
Return type: Returns the pandas data frame having the same content as Pyspark Dataframe.
Get through each column value and add the list of values to the dictionary with the column name as the key.
Python3
dict = {}
df = df.toPandas()
for column in df.columns:
dict[column] = df[column].values.tolist()
print(dict)
|
Output :
{‘Name’: [‘Ram’, ‘Mike’, ‘Rohini’, ‘Maria’, ‘Jenis’],
‘DOB’: [‘1991-04-01’, ‘2000-05-19’, ‘1978-09-05’, ‘1967-12-01’, ‘1980-02-17’],
‘Gender’: [‘M’, ‘M’, ‘M’, ‘F’, ‘F’],
‘salary’: [3000, 4000, 4000, 4000, 1200]}
Method 2: Using df.collect()
Convert the PySpark data frame into the list of rows, and returns all the records of a data frame as a list.
Syntax: DataFrame.collect()
Return type: Returns all the records of the data frame as a list of rows.
Python3
import numpy as np
rows = [list(row) for row in df.collect()]
ar = np.array(rows)
dict = {}
for i, column in enumerate(df.columns):
dict[column] = list(ar[:, i])
print(dict)
|
Output :
{‘Name’: [‘Ram’, ‘Mike’, ‘Rohini’, ‘Maria’, ‘Jenis’],
‘DOB’: [‘1991-04-01’, ‘2000-05-19’, ‘1978-09-05’, ‘1967-12-01’, ‘1980-02-17’],
‘Gender’: [‘M’, ‘M’, ‘M’, ‘F’, ‘F’],
‘salary’: [‘3000’, ‘4000’, ‘4000’, ‘4000’, ‘1200’]}
Method 3: Using pandas.DataFrame.to_dict()
Pandas data frame can be directly converted into a dictionary using the to_dict() method
Syntax: DataFrame.to_dict(orient=’dict’,)
Parameters:
- orient: Indicating the type of values of the dictionary. It takes values such as {‘dict’, ‘list’, ‘series’, ‘split’, ‘records’, ‘index’}
Return type: Returns the dictionary corresponding to the data frame.
Code:
Python3
df = df.toPandas()
dict = df.to_dict(orient = 'list')
print(dict)
|
Output :
{‘Name’: [‘Ram’, ‘Mike’, ‘Rohini’, ‘Maria’, ‘Jenis’],
‘DOB’: [‘1991-04-01’, ‘2000-05-19’, ‘1978-09-05’, ‘1967-12-01’, ‘1980-02-17’],
‘Gender’: [‘M’, ‘M’, ‘M’, ‘F’, ‘F’],
‘salary’: [3000, 4000, 4000, 4000, 1200]}
Converting a data frame having 2 columns to a dictionary, create a data frame with 2 columns naming ‘Location’ and ‘House_price’
Python3
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('DF_to_dict').getOrCreate()
data = [(('Hyderabad'), 120000),
(('Delhi'), 124000),
(('Mumbai'), 344000),
(('Guntur'), 454000),
(('Bandra'), 111200)]
columns = ["Location", 'House_price']
df = spark.createDataFrame(data=data, schema=columns)
print('Dataframe : ')
df.show()
df = df.toPandas()
dict = df.to_dict(orient='list')
print('Dictionary :')
print(dict)
|
Output :

Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...