Convert Factor to Numeric and Numeric to Factor in R Programming
Last Updated :
01 Aug, 2023
Factors are data structures that are implemented to categorize the data or represent categorical data and store it on multiple levels. They can be stored as integers with a corresponding label to every unique integer. Though factors may look similar to character vectors, they are integers, and care must be taken while using them as strings. The factor accepts only a restricted number of distinct values. It is helpful in categorizing data and storing it on multiple levels.
Converting Factors to Numeric Values
In R require to explicitly change factors to either numbers or text. To achieve this, one has to use the functions as.character() or as.numeric(). There are two steps for converting a factor to a numeric:
Step 1: Convert the data vector into a factor. The factor() command is used to create and modify factors in R.
Step 2: The factor is converted into a numeric vector using as.numeric(). When a factor is converted into a numeric vector, the numeric codes corresponding to the factor levels will be returned.
Example: Take a data vector ‘V’ consisting of directions and its factor will be converted into a numeric.
R
V = c("North", "South", "East", "East")
drn <- factor(V)
a1<-as.numeric(drn)
a1
is.numeric(a1)
|
Output:
[1] 2 3 1 1
[1] TRUE
Converting a Factor that is a Number:
If the factor is a number, first convert it to a character vector and then to a numeric. If a factor is a character then you need not convert it to a character. And if you try converting an alphabet character to numeric it will return NA. Example:
Suppose we are taking the costs of soaps of the various brands which are numbers with value s(29, 28, 210, 28, 29).
R
soap_cost <- factor(c(29, 28, 210, 28, 29))
a1<-as.numeric(as.character(soap_cost))
a1
is.numeric(a1)
|
Output:
[1] 29 28 210 28 29
[1] TRUE
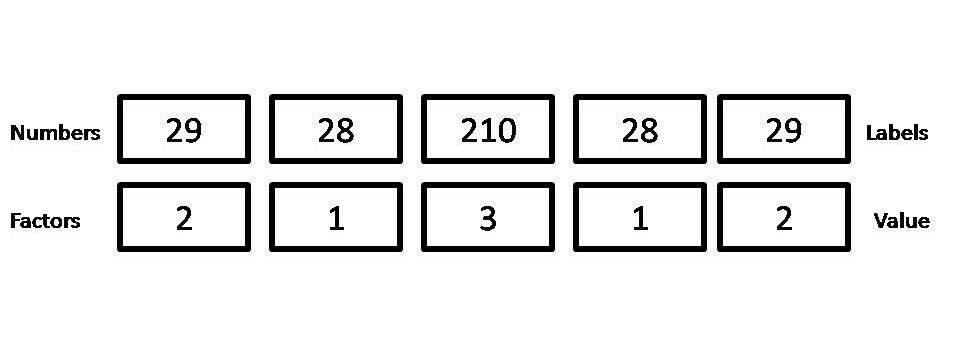 However, if you simply use as. numeric(), the output is a vector of the internal level representations of the factor and not the original values.
However, if you simply use as. numeric(), the output is a vector of the internal level representations of the factor and not the original values.
R
soap_cost <- factor(c(29, 28, 210, 28, 29))
a1<-as.numeric(soap_cost)
a1
is.numeric(a1)
|
Output:
[1] 2 1 3 1 2
[1] TRUE
Converting Numeric value to a Factor
For converting a numeric into a factor we use the cut() function. cut() divides the range of numeric vector(assume x) which is to be converted by cutting into intervals and codes its value (x) according to which interval they fall. Level one corresponds to the leftmost, level two corresponds to the next leftmost, and so on.
Syntax: cut.default(x, breaks, labels = NULL, include.lowest = FALSE, right = TRUE, dig.lab = 3)
where,
- When a number is given through the ‘break=’ argument, the output factor is created by the division of the range of variables into that number of equal-length intervals.
- In syntax include.lowest indicates whether an ‘x[i]’ which equals the lowest (for right= TRUE) break’s value should be included. And ‘right’ in the syntax indicates whether the intervals should be open on the left and closed on the right or vice versa.
- If labels are not provided then dig. lab is used. The number of digits used in formatting the break numbers is determined through it.
Example 1: Lets us assume an employee data set of age, salary, and gender. To create a factor corresponding to age with three equally spaced levels we can write in R as follows:
R
age <- c(40, 49, 48, 40, 67, 52, 53)
salary <- c(103200, 106200, 150200, 10606, 10390, 14070, 10220)
gender <- c("male", "male", "transgender",
"female", "male", "female", "transgender")
employee<- data.frame(age, salary, gender)
wfact = cut(employee$age, 3)
table(wfact)
is.factor(wfact)
|
Output:
wfact
(40,49] (49,58] (58,67]
4 2 1
[1] TRUE
Example 2: We will now put labels- young, medium, and aged.
R
age <- c(40, 49, 48, 40, 67, 52, 53)
salary <- c(103200, 106200, 150200, 10606, 10390, 14070, 10220)
gender <- c("male", "male", "transgender",
"female", "male", "female", "transgender")
employee<- data.frame(age, salary, gender)
wfact = cut(employee$age, 3, labels=c('Young', 'Medium', 'Aged'))
table(wfact)
is.factor(wfact)
|
Output:
wfact
Young Medium Aged
4 2 1
[1] TRUE
The next examples will use ‘norm()‘ for generating multivariate normal distributed random variants within the specified space. There are three arguments given to rnorm():
- n: Number of random variables that need to be generated
- mean: Its value is 0 by default if not mentioned
- sd: standard deviation value needs to be mentioned otherwise it is 1 by default
Syntax:
norm(n, mean, sd)
R
y <- rnorm(100)
a1<-table(cut(y, breaks = pi/3*(-3:3)))
a1
is.numeric(a1)
|
Output:
(-3.14,-2.09] (-2.09,-1.05] (-1.05,0] (0,1.05] (1.05,2.09] (2.09,3.14]
0 10 39 31 19 1
[1] TRUE
The output factor is created by the division of the range of variables into 5 equal-length intervals through break argument.
R
age <- c(40, 49, 48, 40, 67, 52, 53)
gender <- c("male", "male", "transgender", "female", "male", "female",
"transgender")
employee<- data.frame(age, gender)
wfact = cut(employee$age, breaks=5)
table(wfact)
|
Output:
wfact
(40,45.4] (45.4,50.8] (50.8,56.2] (56.2,61.6] (61.6,67]
2 2 2 0 1
R
y <- rnorm(100)
table(cut(y, breaks = pi/3*(-3:3), dig.lab=5))
|
Output:
(-3.1416,-2.0944] (-2.0944,-1.0472] (-1.0472,0] (0,1.0472]
5 13 33 28
(1.0472,2.0944] (2.0944,3.1416]
19 2
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...