Collaborative Filtering in Machine Learning
Last Updated :
31 Mar, 2023
If this time you are watching a horror video on youtube then next time you will automatically see some more horror videos in your feed have you ever thought about how this thing works? Like how an application was able to get to know about your choices and likes. This is exactly what is popularly known as Recommendation Systems.
What is a Recommendation system?
There are a lot of applications where websites collect data from their users and use that data to predict the likes and dislikes of their users. This allows them to recommend the content that they like. Recommender systems are a way of suggesting similar items and ideas to a user’s specific way of thinking.
There are basically two types of recommender Systems:
- Collaborative Filtering: Collaborative Filtering recommends items based on similarity measures between users and/or items. The basic assumption behind the algorithm is that users with similar interests have common preferences.
- Content-Based Recommendation: It is supervised machine learning used to induce a classifier to discriminate between interesting and uninteresting items for the user.
In this article, we will mainly focus on the Collaborative Filtering method.
What is Collaborative Filtering?
In Collaborative Filtering, we tend to find similar users and recommend what similar users like. In this type of recommendation system, we don’t use the features of the item to recommend it, rather we classify the users into clusters of similar types and recommend each user according to the preference of its cluster.
There are basically four types of algorithms o say techniques to build Collaborative filtering based recommender systems:
- Memory-Based
- Model-Based
- Hybrid
- Deep Learning
Advantages of Collaborative Filtering-Based Recommender Systems
As we know there are two types of recommender systems the content-based recommender systems have limited use cases and have higher time complexity. Also, this algorithm is based on some limited content but that is not the case in Collaborative Filtering based algorithms. One of the main advantages that these recommender systems have is that they are highly efficient in providing personalized content but also able t adapt to changing user preferences.
Measuring Similarity
A simple example of the movie recommendation system will help us in explaining: 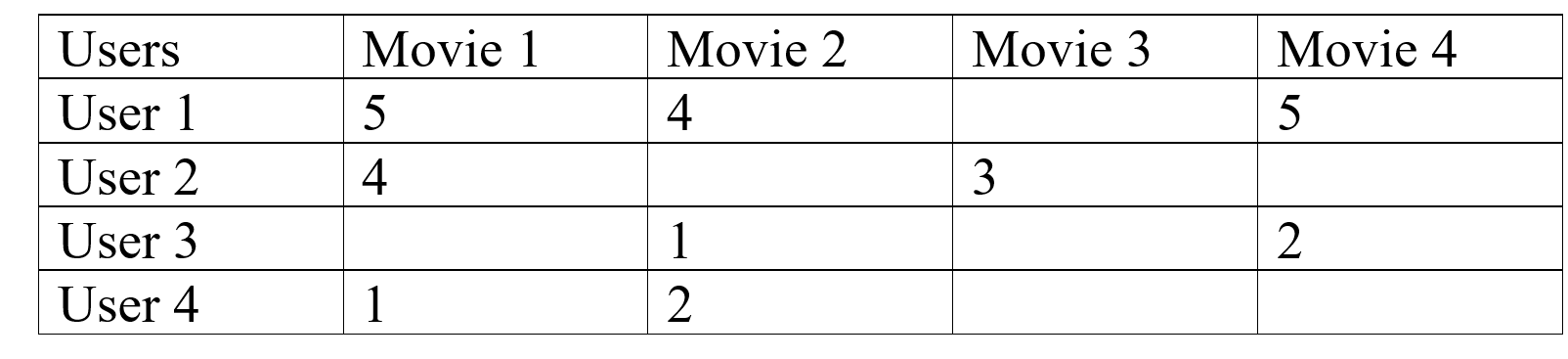 In this type of scenario, we can see that User 1 and User 2 give nearly similar ratings to the movie, so we can conclude that Movie 3 is also going to be averagely liked by User 1 but Movie 4 will be a good recommendation to User 2, like this we can also see that there are users who have different choices like User 1 and User 3 are opposite to each other. One can see that User 3 and User 4 have a common interest in the movie, on that basis we can say that Movie 4 is also going to be disliked by User 4. This is Collaborative Filtering, we recommend to users the items which are liked by users of similar interest domains.
In this type of scenario, we can see that User 1 and User 2 give nearly similar ratings to the movie, so we can conclude that Movie 3 is also going to be averagely liked by User 1 but Movie 4 will be a good recommendation to User 2, like this we can also see that there are users who have different choices like User 1 and User 3 are opposite to each other. One can see that User 3 and User 4 have a common interest in the movie, on that basis we can say that Movie 4 is also going to be disliked by User 4. This is Collaborative Filtering, we recommend to users the items which are liked by users of similar interest domains.
Cosine Similarity
We can also use the cosine similarity between the users to find out the users with similar interests, larger cosine implies that there is a smaller angle between two users, hence they have similar interests. We can apply the cosine distance between two users in the utility matrix, and we can also give the zero value to all the unfilled columns to make calculation easy, if we get smaller cosine then there will be a larger distance between the users, and if the cosine is larger than we have a small angle between the users, and we can recommend them similar things.
*** QuickLaTeX cannot compile formula:
\text{similarity} = \frac{A\cdot B}{\left\| A\right\|\times \left\| B\right\|}=\frac{\sum_{i=1}^{n}A_i \times B_i}{\sqrt{\sum_{i=1}^{n}A_i^2}\times {\sqrt{\sum_{i=1}^{n}B_i^2}}
*** Error message:
File ended while scanning use of \frac .
Emergency stop.
Rounding the Data
In collaborative filtering, we round off the data to compare it more easily like we can assign below 3 ratings as 0 and above of it as 1, this will help us to compare data more easily, for example: 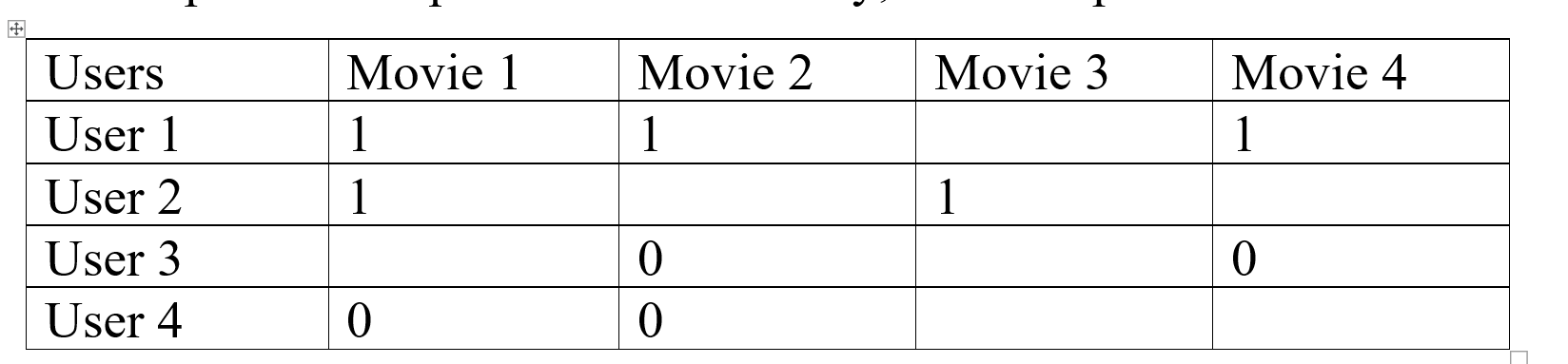 We again took the previous example and we apply the rounding-off process, as you can see how much more readable the data has become after performing this process, we can see that User 1 and User 2 are more similar and User 3 and User 4 are more alike.
We again took the previous example and we apply the rounding-off process, as you can see how much more readable the data has become after performing this process, we can see that User 1 and User 2 are more similar and User 3 and User 4 are more alike.
Normalizing Rating
In the process of normalizing, we take the average rating of a user and subtract all the given ratings from it, so we’ll get either positive or negative values as a rating, which can simply classify further into similar groups. By normalizing the data we can make clusters of the users that give a similar rating to similar items and then we can use these clusters to recommend items to the users.
What are some of the Challenges to be Faced while using Collaborative Filtering?
As we know that every algorithm has its pros and cons and so is the case with Collaborative Filtering Algorithms. Collaborative Filtering algorithms are very dynamic and can change as well as adapt to the changes in user preferences with time. But one of the main issues which are faced by recommender systems is that of scalability because as the user base increases then the respective sizes for the computation and the data storage space all increase manifold which leads to slow and inaccurate results.
Also, collaborative filtering algorithms fail to recommend a diversity of products as it is based on historical data and hence provide recommendations related to them as well.
Read more about – Collaborative Filtering Recommender Systems
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...