Caching Page Tables
Last Updated :
12 May, 2023
Paging is a memory management scheme which allows physical address space of a process to be non-contiguous. The basic idea of paging is to break physical memory into fixed-size blocks called frames and logical memory into blocks of same size called pages. While executing the process the required pages of that process are loaded into available frames from their source that is disc or any backup storage device.
CPU generates logical address for the process which is divided into page number and page offset. The page table contains the base address of each page in physical memory. The base address combined with the page offset defines the physical memory address. The page number is used as an index into a page table. Page table is kept in main memory and a page table base register (PTBR) points to the page table.
To access a location x, find entry in the page table, using the value in the PTBR offset by the page number for x. The page table entry gives the frame number, which is combined with the page offset to produce the actual address. We can then access the required memory location. Thus to access a location x , two memory accesses are required reducing the speed of the operation.
A special, small, fast, lookup hardware cache called Translation Lookaside Buffer (TLB) is used to cache small number of entries from the page table. Each TLB entry consists of two parts: key(or tag) and value, here key is the page number and value is the frame number. All the entries of TLB are compared simultaneously with page number, the search is thus fast. A TLB typically contains 32–1024 entries. TLB is a hardware cache and modern computers implement it as a part of instruction pipeline thus causing no overhead of TLB search.
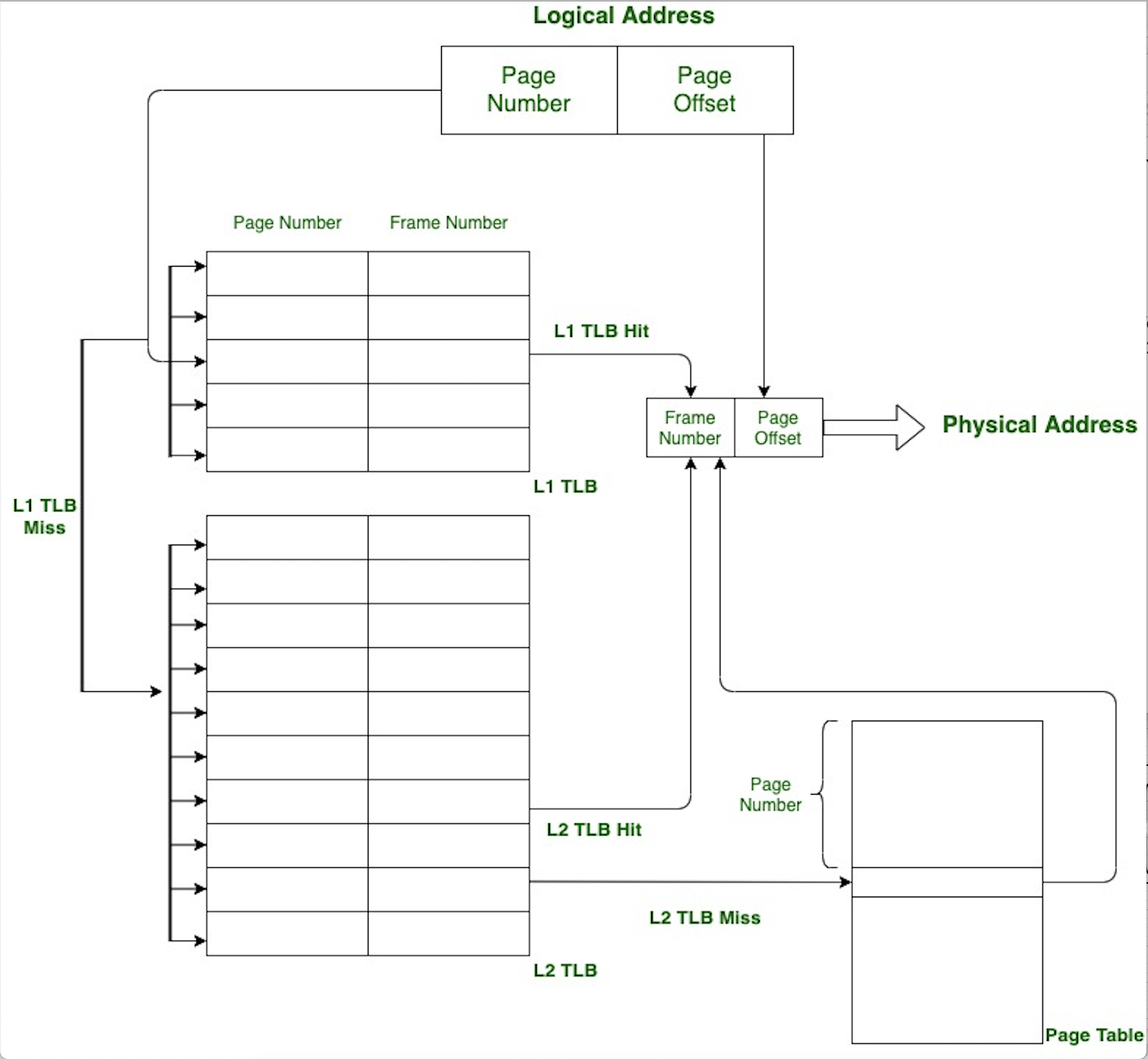
If a page number is not found in TLB , it is called as a TLB miss, the corresponding frame number is taken from the page table and TLB is updated. Now if TLB is already full, an entry of TLB needs to be replaced with this new entry. Various policies are used for such replacement like Least Recently Used (LRU) , round-robin or random replacement.
CPU today provides multi-level TLB. In case of L1 TLB miss, it is searched in L2 TLB and then in page table if L2 TLB is also a miss.The percentage of times that the page number of interest is found in the TLB is called the hit ratio (hit rate) and the percentage of times it is not found in the TLB is called the miss ratio (miss rate). Modern day systems have TLB miss rate of 0.1–1%, thus reducing overhead of accessing the page tables to a large extent.
Some TLBs also store Address-Space Identifiers(ASIDS) in each TLB entry. It uniquely identifies each process and when translation of logical address to physical address is done, only those TLB entries are checked which belong to that process, if no such entry is found it is considered TLB miss. This allows TLB to have entries for several processes simultaneously.If TLB does not allow ASIDS, then every time a context switch happens (change the executing process from one process to another), the TLB needs to be flushed or erased to ensure that next executing process do not use the translation information from the previous process.
Each TLB entry has a valid/invalid bit associated with it which signifies whether the TLB entry is valid or not. This is particularly useful when TLB is flushed, no actual deletion of TLB entry takes place, only all the entries of TLB are invalidated. Thus, before using the TLB entry for translation it is checked whether the entry is valid or not. Also, in case of TLB miss while updating a TLB entry, invalid entries are updated first.
There are several other bits in a TLB entry like global bit(G) which is used for pages that are shared globally across processes, several bits for ASID (ignored for shared pages), dirty bit (to determine if the page has to be written) etc. All these bits are used in a general TLB entry. However, the actual size of entry, various protection bits in TLB entry, number of levels in TLB, number of TLB entries in each level etc varies from architecture to architecture.
Caching Page Tables is a technique used in virtual memory systems to improve the performance of memory accesses. In a traditional virtual memory system, the Page Table is stored in main memory and accessed whenever a memory access is performed. This can result in a significant overhead, as the time required to access the Page Table can be much longer than the time required to access the actual data.
To reduce this overhead, some virtual memory systems use a technique known as Page Table Caching. In Page Table Caching, a portion of the Page Table is stored in a cache, such as the Translation Lookaside Buffer (TLB) in the CPU. This allows for faster access to the Page Table and reduces the number of memory accesses required to perform a memory operation.
The cache used for Page Table Caching is typically a small, high-speed memory that is located on the CPU. When a memory access is performed, the CPU first checks the TLB to see if the required mapping is already present. If the mapping is present, the CPU can immediately access the corresponding physical memory location without accessing the main memory Page Table. If the mapping is not present in the TLB, a Page Table lookup is performed and the mapping is added to the TLB for future use.
Page Table Caching can provide significant performance improvements for memory access operations, especially in systems with large virtual address spaces. However, there are some limitations to this technique, such as the limited size of the TLB and the potential for cache misses when accessing virtual memory pages that are not currently present in the TLB. To mitigate these limitations, some systems use additional levels of caching, such as multi-level Page Table Caches or Translation Lookaside Buffers with larger sizes or more efficient replacement algorithms.
Hardware Support for Paging:
- Memory Management Unit (MMU) for address translation.
- Translation Lookaside Buffer (TLB) for caching frequently accessed page table entries.
- Address translation caches, like the Address Translation Cache (ATC), for faster address translation.
- TLB management mechanisms for handling TLB misses and efficient entry replacement.
- Hardware-based page table walkers for optimized page table traversals.
- Translation caches and buffering structures, such as MicroTLB or MiniTLB, for faster address translation closer to the CPU.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...