Boyer Moore Algorithm | Good Suffix heuristic
Last Updated :
08 Oct, 2023
We have already discussed
Bad character heuristic
variation of Boyer Moore algorithm. In this article we will discuss
Good Suffix
heuristic for pattern searching. Just like bad character heuristic, a preprocessing table is generated for good suffix heuristic.
Good Suffix Heuristic
Let
t
be substring of text
T
which is matched with substring of pattern
P
. Now we shift pattern until : 1) Another occurrence of t in P matched with t in T. 2) A prefix of P, which matches with suffix of t 3) P moves past t
Case 1: Another occurrence of t in P matched with t in T
Pattern P might contain few more occurrences of
t
. In such case, we will try to shift the pattern to align that occurrence with t in text T. For example-
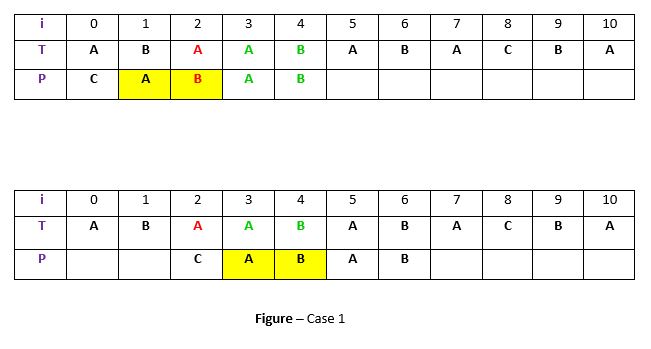
Explanation:
In the above example, we have got a substring t of text T matched with pattern P (in green) before mismatch at index 2. Now we will search for occurrence of t (“AB”) in P. We have found an occurrence starting at position 1 (in yellow background) so we will right shift the pattern 2 times to align t in P with t in T. This is weak rule of original Boyer Moore and not much effective, we will discuss a
Strong Good Suffix rule
shortly.
Case 2: A prefix of P, which matches with suffix of t in T
It is not always likely that we will find the occurrence of t in P. Sometimes there is no occurrence at all, in such cases sometimes we can search for some
suffix of t
matching with some
prefix of P
and try to align them by shifting P. For example –
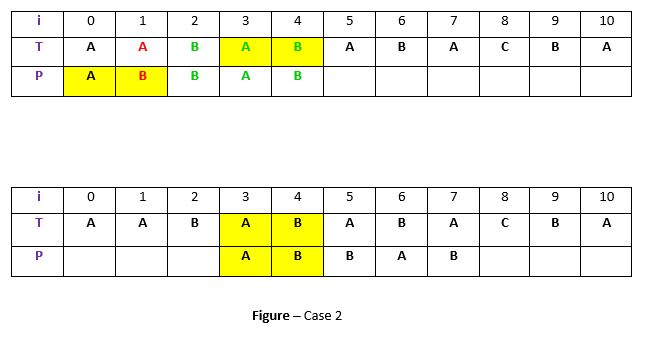
Explanation:
In above example, we have got t (“BAB”) matched with P (in green) at index 2-4 before mismatch . But because there exists no occurrence of t in P we will search for some prefix of P which matches with some suffix of t. We have found prefix “AB” (in the yellow background) starting at index 0 which matches not with whole t but the suffix of t “AB” starting at index 3. So now we will shift pattern 3 times to align prefix with the suffix.
Case 3: P moves past t
If the above two cases are not satisfied, we will shift the pattern past the t. For example –
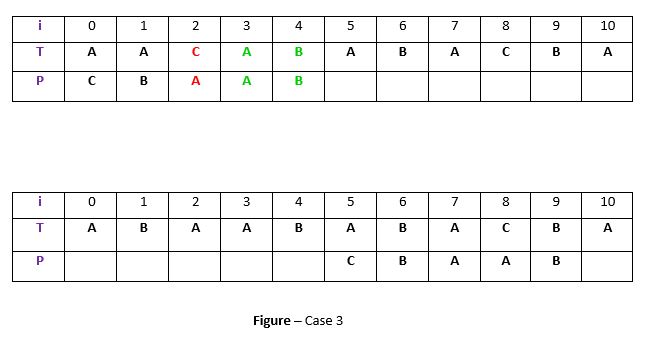
Explanation:
If above example, there exist no occurrence of t (“AB”) in P and also there is no prefix in P which matches with the suffix of t. So, in that case, we can never find any perfect match before index 4, so we will shift the P past the t ie. to index 5.
Strong Good suffix Heuristic
Suppose substring
q = P[i to n]
got matched with
t
in T and
c = P[i-1]
is the mismatching character. Now unlike case 1 we will search for t in P which is not preceded by character
c
. The closest such occurrence is then aligned with t in T by shifting pattern P. For example –
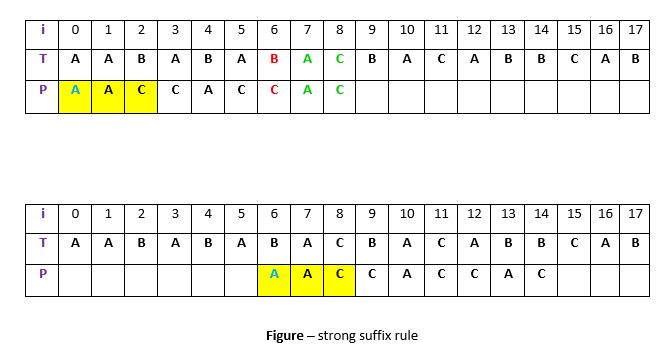
Explanation:
In above example,
q = P[7 to 8]
got matched with t in T. The mismatching character
c
is “C” at position P[6]. Now if we start searching t in P we will get the first occurrence of t starting at position 4. But this occurrence is preceded by “C” which is equal to c, so we will skip this and carry on searching. At position 1 we got another occurrence of t (in the yellow background). This occurrence is preceded by “A” (in blue) which is not equivalent to c. So we will shift pattern P 6 times to align this occurrence with t in T.We are doing this because we already know that character
c = “C”
causes the mismatch. So any occurrence of t preceded by c will again cause mismatch when aligned with t, so that’s why it is better to skip this.
Preprocessing for Good suffix heuristic
As a part of preprocessing, an array
shift
is created. Each entry
shift[i]
contain the distance pattern will shift if mismatch occur at position
i-1
. That is, the suffix of pattern starting at position
i
is matched and a mismatch occur at position
i-1
. Preprocessing is done separately for strong good suffix and case 2 discussed above.
1) Preprocessing for Strong Good Suffix
Before discussing preprocessing, let us first discuss the idea of border. A
border
is a substring which is both proper suffix and proper prefix. For example, in string
“ccacc”
,
“c”
is a border,
“cc”
is a border because it appears in both end of string but
“cca”
is not a border. As a part of preprocessing an array
bpos
(border position) is calculated. Each entry
bpos[i]
contains the starting index of border for suffix starting at index i in given pattern P. The suffix
?
beginning at position m has no border, so
bpos[m]
is set to
m+1
where
m
is the length of the pattern. The shift position is obtained by the borders which cannot be extended to the left. Following is the code for preprocessing –
void preprocess_strong_suffix(int *shift, int *bpos,
char *pat, int m)
{
int i = m, j = m+1;
bpos[i] = j;
while(i > 0)
{
while(j <= m && pat[i-1] != pat[j-1])
{
if (shift[j] == 0)
shift[j] = j-i;
j = bpos[j];
}
i--; j--;
bpos[i] = j;
}
}
Explanation:
Consider pattern
P = “ABBABAB”, m = 7
.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...