For understanding the concept behind Machine Learning, as well as Deep Learning, Linear Algebra principles, are crucial. Linear algebra is a branch of mathematics that allows us to define and perform operations on higher-dimensional coordinates and plane interactions in a concise way. Its main focus is on linear equation systems.
In linear algebra, a basis vector refers to a vector that forms part of a basis for a vector space. A basis is a set of linearly independent vectors that can be used to represent any vector within that vector space. Basis vectors play a fundamental role in describing and analyzing vectors and vector spaces.
The basis of a vector space provides a coordinate system that allows us to represent vectors using numerical coordinates.
Some important Terminolgy
- Vector Space (V): Vector Space (V) is a mathematical structure of a set of vectors that can do addition and scalar multiplication. A set of vectors and operations that are defined on those vectors make up a mathematical structure called a vector space.
Example: V = {(x, y) | x, y ∈ ℝ}
- Field (F): Field is the name of the scalar field over which the vector space V is defined. It offers the coefficients used in linear vector combinations. Common examples of fields are real numbers (R), complex numbers (C), and rational numbers (Q).
- Basis (B): A collection of linearly independent vectors that span the entire vector space V is referred to as a basis for vector space V.
Example: The basis for the Vector space V = [x,y] having two vectors i.e x and y will be :
[Tex]B = \left \{ \begin{bmatrix}
1\\
0
\end{bmatrix},\begin{bmatrix}
0\\
1
\end{bmatrix} \right \}[/Tex]
Basis Vector
In a vector space, if a set of vectors can be used to express every vector in the space as a unique linear combination of those vectors, and those vectors are linearly independent (meaning that none of them can be expressed as a linear combination of the others), then we refer to them as basis vectors for that vector space.
To summarize:
- Basis vectors are a set of vectors that span the entire vector space.
- They are linearly independent, meaning that no vector in the set can be written as a linear combination of the other vectors.
- Every vector in the vector space can be expressed uniquely as a linear combination of the basis vectors.
The basis of a vector space provides a coordinate system that allows us to represent vectors using numerical coordinates. It serves as a reference or framework for describing vectors in terms of their components.
Several branches of mathematics and applications, including linear algebra, geometry, physics, and machine learning, depend on basis vectors. They serve as a foundation for understanding vector spaces, transformations, and the solution of linear equations.
Properties of Basis vector:
Let V be the vector space of dimension n over the Field F and B as the basis for vector space V i.e a set of vectors {v1, v2, …, vn} which have to satisfy the following two conditions:
- Basis vectors must be linearly independent of each other:
This means that no basis vector can be expressed as a linear combination of the others. If we take any two basis vectors, such as v1 and v2, multiplying v1 by any scalar should not yield v2. This property ensures that each basis vector contributes unique information to the vector space. If we multiply v1 by any scalar, we will never be able to get the vector v2. And that proves that v1 and v2 are linearly independent of each other. We want basis vectors to be linearly independent of each other because we want every vector, that is on the basis to generate unique information. If they become dependent on each other, then this vector is not going to bring in anything unique. - Basis vectors must span the whole space:
The entire vector space must be spanned by basis vectors. This means any vector in the space can be written as a linear combination of the basis vectors. In other words, all points in the vector space can be reached by the linear combinations of the basis vectors. It ensures that we can use the basis vectors to represent any vector in the space.
A subset B of V spans V if every vector in V can be expressed as a linear combination of vectors from B. In other words, for any vector v in V, there exist coefficients a₁, a₂, …, aₙ in F and vectors v1, v2, …, vn in B such that V = a₁v₁ + a₂v₂ + … + aₙvₙ. - Non-Uniqueness of Basis Vectors:
The non-uniqueness of basis vectors refers to the fact the choice of basis vectors is not unique, and different sets of vectors can form a basis for the same vector space. However, once a basis is chosen, any vector in the vector space can be uniquely represented as a linear combination of the basis vectors, with the coefficients being the coordinates or components of the vector with respect to that basis.
If you can write every vector in a given space as a linear combination of some vectors and these vectors are independent of each other then we call them basis vectors for that given space.
ℝ2 Vector Space
Let us take an R-squared space which basically means that, we are looking at vectors in 2 dimensions. It means that there are 2 components in each of these vectors as we have taken in the above image. We can take many vectors. So, there will be an infinite number of vectors, which will be in 2 dimensions. So, the point is can we represent all of these vectors using some basic elements and then some combination of these basic elements?
The vector space for two dimensional can be represented as below:
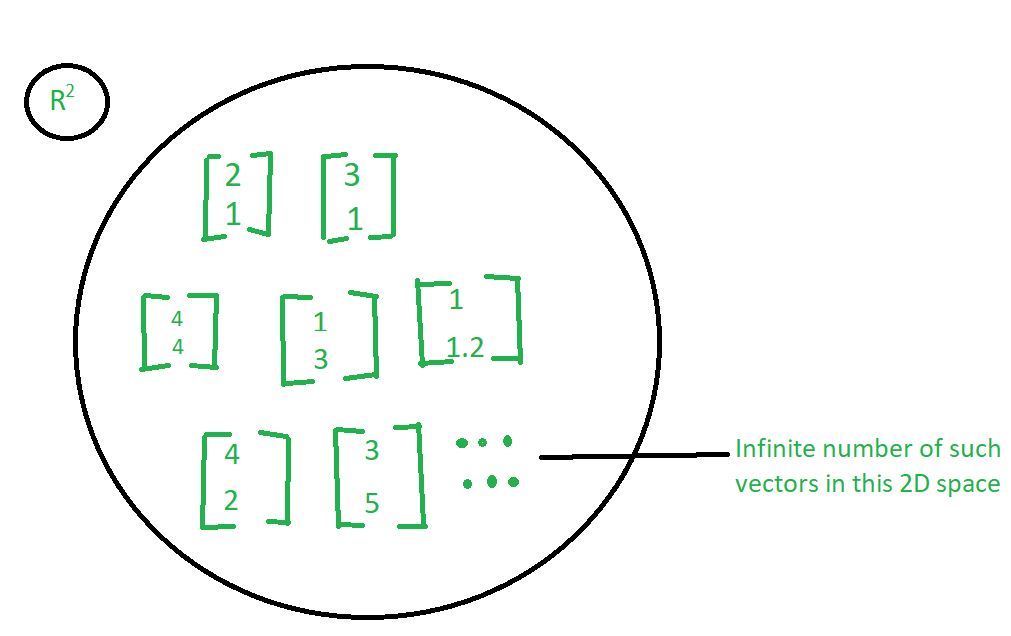
ℝ2 vector space
Let’s consider a simple example where we have a two-dimensional vector space. In this case, the standard basis vectors are shown below:
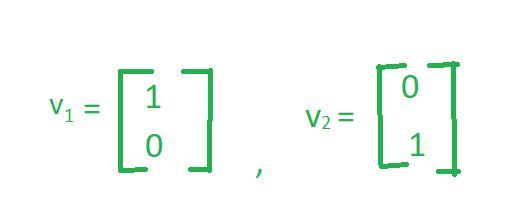
ℝ2 Basis Vector
These two basis vectors span the entire vector space.
Let’s say we want to find the basis vectors for a given vector v = 2i+1j. To determine the coefficients of the linear combination of the basis vectors that form the vector v, we can set up the following equation:
[Tex]V = a_1\begin{bmatrix}
1\\
0
\end{bmatrix}+a_2\begin{bmatrix}
0\\
1
\end{bmatrix}[/Tex]
where ‘a1‘ and ‘a2‘ are the coefficients we need to find.
To solve for ‘a1‘ and ‘a2‘, we can equate the corresponding components of both sides of the equation:
a1=2
a2=1
Thus, the coefficients ‘a1‘ and ‘a2‘ are 2 and 1, respectively. Therefore, the basis vectors for v are:
[Tex]\begin{aligned} v &= a_1\begin{bmatrix}1\\ 0\end{bmatrix}+a_2\begin{bmatrix}0\\ 1\end{bmatrix} \\ &= 2\begin{bmatrix}1\\ 0\end{bmatrix} + 1\begin{bmatrix}0\\ 1\end{bmatrix} \\ &= \begin{bmatrix}2\\ 0 \end{bmatrix} + \begin{bmatrix}0\\ 1\end{bmatrix} \\ &= \begin{bmatrix}2\\ 1\end{bmatrix} \end{aligned}[/Tex]
In this case, the basis vectors for [Tex]v = \begin{bmatrix}2\\ 1\end{bmatrix} [/Tex] are [Tex]\begin{bmatrix} 0\\ 1 \end{bmatrix} [/Tex] themselves, as they can be linearly combined with the coefficients 2 and 1, respectively, to obtain v.
Python3
import numpy as np
v = np.array([2, 1])
basis = np.eye(2)
print('Standard Basis Vector:\n',basis)
coefficients = np.linalg.solve(basis, v)
print('coefficients :',coefficients)
basis_vectors = coefficients * basis
print('Basis vectors for above coefficients:\n',basis_vectors)
|
Output:
Standard Basis Vector:
[[1. 0.]
[0. 1.]]
coefficients : [2. 1.]
Basis vectors for above coefficients:
[[2. 0.]
[0. 1.]]
- Similarly, if you take the vector(1,3)
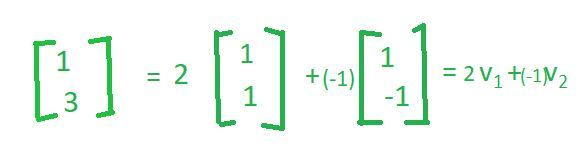
- Similarly, if you take the vector(4,4)
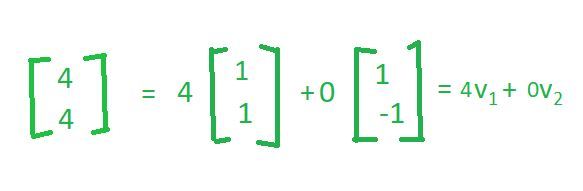
- So, this is another linear combination of the same basis vectors. So, the key point that I want to make here is that the basis vectors are not unique. There are many ways in which we can define the basis vectors; however, they all share the same property that, if I have a set of vectors that I call a basis vector, those vectors have to be independent of each other and they should span the whole space.
Hence, this v1 and v2 are also basis vectors for R2.
Point to remember:
An interesting thing to note here is that we cannot have 2 basis sets that have a different number of vectors. What I mean here is in the previous example though the basis vectors were v1(1, 0) and v2(0, 1) there were only 2 vectors. Similarly, in this case, the basis vectors are v1(1, 1) and v2(1, -1). However, there are still only 2 vectors. So, while you could have many sets of basis vectors, all of them being equivalent to the number of vectors in each set will be the same, they cannot be different. So something that you should keep in mind is that for the same space, you can not have 2 basis sets one with n vectors and another one with m vectors that is not possible. So, if it is a basic set for the same space, the number of vectors in each set should be the same.
When working with vector components, it’s crucial to consider the basis that is being used. The components of a vector are defined with respect to a specific basis, and if you change the basis, the component values will be different
Find basis vectors for R4 Vector Space:
Let’s take an example of R4 space. What it actually means is that there are 4 components in each of these vectors.
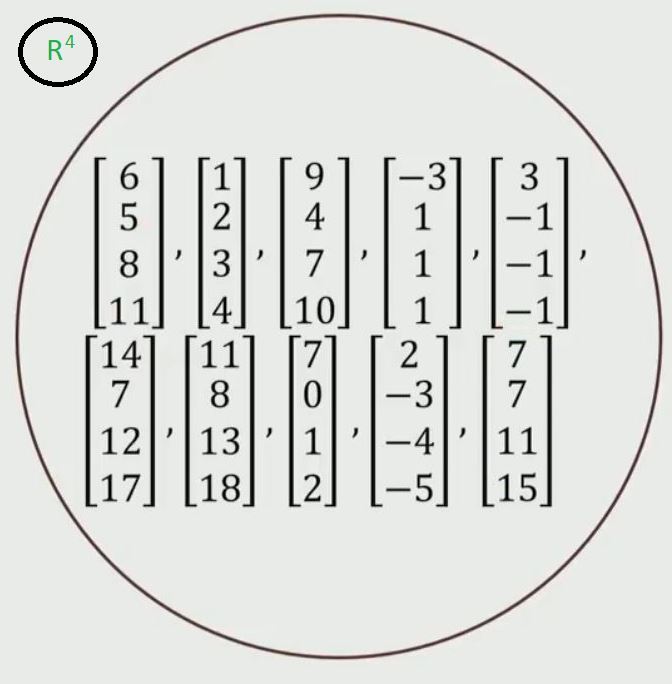
R4 Vector Space
- Step 1: To find the basis vectors of the given set of vectors, arrange the vectors in matrix form as shown below.
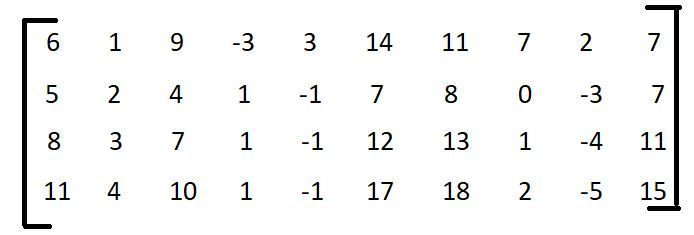
- Step 2: Find the rank of this matrix.
If you identify the rank of this matrix it will give you the number of linearly independent columns. The rank of the matrix will tell us, how many are fundamental to explaining all of these columns, and how many columns we need. So, that we can generate the remaining columns as a linear combination of these columns. - Step 3:
Any two independent columns can be picked from the above matrix as basis vectors.
Find the standard basis vector for the same vector space
Python3
import numpy as np
u = np.array([6, 5, 8, 11])
magnitude_u = np.linalg.norm(u)
unit_vector_u = u / magnitude_u
basis_vectors = []
for i in range(len(unit_vector_u)):
if unit_vector_u[i] != 0:
basis_vectors.append(np.eye(len(unit_vector_u))[i])
basis_vectors = np.array(basis_vectors)
basis_vectors
|
Output:
array([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
Check
Output:
array([ 6., 5., 8., 11.])
Explanation:
If the rank of the matrix is 1 then we have only 1 basis vector, if the rank is 2 then there are 2 basis vectors if 3 then there are 3 basis vectors, and so on. In this case, since the rank of the matrix turns out to be 2, there are only 2 column vectors that I need to represent every column in this matrix. So, the basis set has size 2. So, we can pick any 2 linearly independent columns here and then those could be the basis vectors.
So, for example, we could choose v1(6, 5, 8, 11) and v2(1, 2, 3, 4) and say, this is the basis vector for all of these columns or we could choose v1(3, -1, -1, -1) and v2(7, 7, 11, 15) and so on. We can choose any 2 columns as long as they are linearly independent of each other and this is something that we know from above that the basis vectors need not be unique. So, I pick any 2 linearly independent columns that represent this data.
Important from a data science viewpoint
Now, let me explain to you why this basis vectors concept is very important from a data science viewpoint. Just take a look at the previous example. We have 10 samples and we want to store these 10 samples since each sample has 4 numbers, we would be storing 4 x 10 = 40 numbers.
Now, let us assume we do the same exercise, for these 10 samples and then we find that we have only 2 basis vectors, which are going to be 2 vectors out of this set. What we could do is, we could store these 2 basis vectors that, would be 2 x 4 = 8 numbers and for the remaining 8 samples, instead of storing all the samples and all the numbers in each of these samples, what we could do is for each sample we could just store 2 numbers, which are the linear combinations that we are going to use to construct this. So, instead of storing these 4 numbers, we could simply store those 2 constants and since we already have stored the basis vectors, whenever we want to reconstruct this, we can simply take the first constant and multiply it by v1 plus the second constant multiply it by v2 and we will get this number.
So in summary,
We store 2 basis vectors which give me: 4 x 2 = 8 numbers
And then for the remaining 8 samples, we simply store 2 constants e.g: 8 x 2 = 16 numbers
So, this would give us: 8 + 16 = 24 numbers
Hence instead of storing 4 x 10 = 40 numbers, we can store only 24 numbers,
which is the approximately half reduction in number.
And we will be able to reconstruct the whole data set by storing only 24 numbers.
So, for example, if you have a 30-dimensional vector and the basis vectors are just 3, then you can see the kind of reduction, that you will get in terms of data storage. So, this is one viewpoint of data science.
Why is the reduction in data storage going to benefit from a data science viewpoint?
It is very important to understand and characterize the data in terms of what fundamentally characterizes the data. So, that you can store less, we can do smarter computations and there are many other reasons why we will want to do this,
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...