Basic Understanding of CURE Algorithm
Last Updated :
31 Aug, 2021
CURE(Clustering Using Representatives)
- It is a hierarchical based clustering technique, that adopts a middle ground between the centroid based and the all-point extremes. Hierarchical clustering is a type of clustering, that starts with a single point cluster, and moves to merge with another cluster, until the desired number of clusters are formed.
- It is used for identifying the spherical and non-spherical clusters.
- It is useful for discovering groups and identifying interesting distributions in the underlying data.
- Instead of using one point centroid, as in most of data mining algorithms, CURE uses a set of well-defined representative points, for efficiently handling the clusters and eliminating the outliers.

Representation of Clusters and Outliers
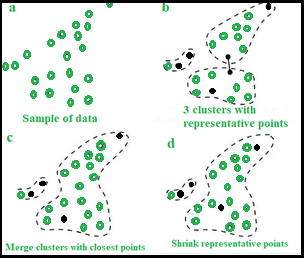
Six steps in CURE algorithm:

CURE Architecture
- Idea: Random sample, say ‘s’ is drawn out of a given data. This random sample is partitioned, say ‘p’ partitions with size s/p. The partitioned sample is partially clustered, into say ‘s/pq’ clusters. Outliers are discarded/eliminated from this partially clustered partition. The partially clustered partitions need to be clustered again. Label the data in the disk.

Representation of partitioning and clustering
- Procedure :
- Select target sample number ‘gfg’.
- Choose ‘gfg’ well scattered points in a cluster.
- These scattered points are shrunk towards centroid.
- These points are used as representatives of clusters and used in ‘Dmin’ cluster merging approach. In Dmin(distance minimum) cluster merging approach, the minimum distance from the scattered point inside the sample ‘gfg’ and the points outside ‘gfg sample, is calculated. The point having the least distance to the scattered point inside the sample, when compared to other points, is considered and merged into the sample.
- After every such merging, new sample points will be selected to represent the new cluster.
- Cluster merging will stop until target, say ‘k’ is reached.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...