Avinash Lakshman and Prashant Malik initially developed Cassandra at Facebook to power the Facebook inbox search feature. Facebook released Cassandra as an open source project on google code in July 2008. It became an Apache incubator project in March 2009. It became one of the top level project in 17 Feb 2010. Fueled by the internet revolution, mobile devices, and e-commerce, modern applications have outgrown relational databases. Out of necessity, a new generation of databases has emerged to address large-scale, globally distributed data management challenges.
Cassandra powers online services and mobile backend for some of the world’s most recognizable brands, including Apple, Netflix, and Facebook.
Architecture of Apache Cassandra:
In this section we will describe the following component of Apache Cassandra.
Basic Terminology:
Node
Data center
Cluster
Operations:
Read Operation
Write Operation
Storage Engine:
CommitLog
Memtables
SSTables
Data Replication Strategies
let’s discuss one by one.
Basic Terminology:
1. Node:
Node is the basic component in Apache Cassandra. It is the place where actually data is stored. For Example:As shown in diagram node which has IP address 10.0.0.7 contain data (keyspace which contain one or more tables).

Figure – Node
2. Data Center:
Data Center is a collection of nodes.
For example:
DC – N1 + N2 + N3 ….
DC: Data Center
N1: Node 1
N2: Node 2
N3: Node 3
3. Cluster:
It is the collection of many data centers.
For example:
C = DC1 + DC2 + DC3….
C: Cluster
DC1: Data Center 1
DC2: Data Center 2
DC3: Data Center 3

Figure – Node, Data center, Cluster
Operations:
1. Read Operation:
In Read Operation there are three types of read requests that a coordinator can send to a replica. The node that accepts the write requests called coordinator for that particular operation.
- Step-1: Direct Request:
In this operation coordinator node sends the read request to one of the replicas.
- Step-2: Digest Request:
In this operation coordinator will contact to replicas specified by the consistency level. For Example: CONSISTENCY TWO; It simply means that Any two nodes in data center will acknowledge.
- Step-3: Read Repair Request:
If there is any case in which data is not consistent across the node then background Read Repair Request initiated that makes sure that the most recent data is available across the nodes.
2. Write Operation:
- Step-1:
In Write Operation as soon as we receives request then it is first dumped into commit log to make sure that data is saved.
- Step-2:
Insertion of data into table that is also written in MemTable that holds the data till it’s get full.
- Step-3:
If MemTable reaches its threshold then data is flushed to SS Table.

Figure – Write Operation in Cassandra
Storage Engine:
- Commit log:
Commit log is the first entry point while writing to disk or memTable. The purpose of commit log in apache Cassandra is to server sync issues if a data node is down.
- Mem-table:
After data written in Commit log then after that data is written in Mem-table. Data is written in Mem-table temporarily.
- SSTable:
Once Mem-table will reach a certain threshold then data will flushed to the SSTable disk file.
Data Replication Strategy:
Basically it is used for backup to ensure no single point of failure. In this strategy Cassandra uses replication to achieve high availability and durability. Each data item is replicated at N hosts, where N is the replication factor configured \per-instance”.
There are two type of replication Strategy: Simple Strategy, and Network Topology Strategy. These are explained as following below.
1. Simple Strategy:
In this Strategy it allows a single integer RF (replication_factor) to be defined. It determines the number of nodes that should contain a copy of each row. For example, if replication_factor is 2, then two different nodes should store a copy of each row. It treats all nodes identically, ignoring any configured datacenters or racks.
CQL(Cassandra Query language) query for Simple Strategy. A keyspace is created using a CREATE KEYSPACE statement:
create_keyspace_statement ::=
CREATE KEYSPACE [ IF NOT EXISTS ] keyspace_name
WITH options
For instance:
CREATE KEYSPACE User_data
WITH replication = {'class': 'SimpleStrategy',
'replication_factor' : 2};
To check keyspace Schema used the following CQl query.
DESCRIBE KEYSPACE User_data
Pictorial Representation of Simple Strategy.

Figure – Simple Strategy
2. Network Topology Strategy:
In this strategy it allows a replication factor to be specified for each datacenter in the cluster. Even if your cluster only uses a single datacenter. This Strategy should be preferred over SimpleStrategy to make it easier to add new physical or virtual datacenters to the cluster later.
CQL(Cassandra Query language) query for Network Topology Strategy.
CREATE KEYSPACE User_data
WITH replication = {'class': 'NetworkTopologyStrategy', 'DC1' : 2, 'DC2' : 3}
AND durable_writes = false;
To check keyspace Schema used the following CQl query.
DESCRIBE KEYSPACE User_data
Pictorial Representation of Network Topology Strategy.

Figure – Network Topology Strategy
Table Structure in Cassandra:
USE User_data;
CREATE TABLE User_table (
User_id int,
User_name text,
User_add text,
User_phone text,
PRIMARY KEY (User_id)
);
Insert into User_data (User_id, User_name, User_add, User_phone )
VALUES(1000, ‘Ashish’, ‘Noida’, ‘8077178539’);
Insert into User_data (User_id, User_name, User_add, User_phone )
VALUES(1001, ‘Ashish Gupta’, ‘Bangalore’);
Insert into User_data (User_id, User_name, User_add, User_phone )
VALUES(1002, ‘Abi’);
Output:
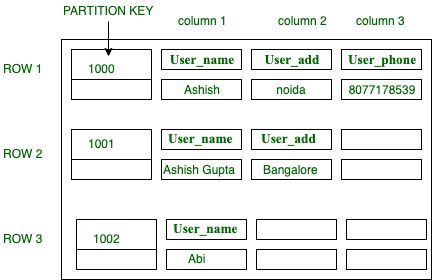
Figure – Table Structure
Application of Apache Cassandra:
Some of the application use cases that Cassandra excels in include:
- Real-time, big data workloads
- Time series data management
- High-velocity device data consumption and analysis
- Media streaming management (e.g., music, movies)
- Social media (i.e., unstructured data) input and analysis
- Online web retail (e.g., shopping carts, user transactions)
- Real-time data analytics
- Online gaming (e.g., real-time messaging)
- Software as a Service (SaaS) applications that utilize web services
- Online portals (e.g., healthcare provider/patient interactions)
- Most write-intensive systems
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...