Append data to an empty Pandas DataFrame
Last Updated :
17 Aug, 2020
Let us see how to append data to an empty Pandas DataFrame.
Creating the Data Frame and assigning the columns to it
import pandas as pd
a = [[1, 1.2], [2, 1.4], [3, 1.5], [4, 1.8]]
t = pd.DataFrame(a, columns =["A", "B"])
print(t)
print(t.dtypes)
|
Output :

On appending the float values to the int valued data type column the resultant data frame column type-caste into float in order to accommodate the float value
If we use the argument ignore_index = True => that the index values will remain continuous instead of starting again from 0, be default it’s value is False
s = pd.DataFrame([[1.3, 9]], columns = ["A", "B"])
display(s)
t = t.append(s, ignore_index = True)
display(t)
display(t.dtypes)
|
Output :

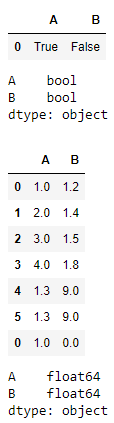
When we appended the boolean format data into the data frame that was already of the type of float columns then it will change the values accordingly in order to accommodate the boolean values in the float data type domain only.
u = pd.DataFrame([[True, False]], columns =["A", "B"])
display(u)
display(u.dtypes)
t = t.append(u)
display(t)
display(t.dtypes)
|
Output :
On appending the data of different data types to the previously formed Data Frame then the resultant Data Frame columns type will always be of the wider spectrum data type.
x = pd.DataFrame([["1.3", "9.2"]], columns = ["A", "B"])
display(x)
display(x.dtypes)
t = t.append(x)
display(t)
display(t.dtypes)
|
Output :

If we aim to create a data frame through a for loop then the most efficient way of doing that is as follows :
y = pd.concat([pd.DataFrame([[i, i * 10]], columns = ["A", "B"])
for i in range(7, 10)], ignore_index = True)
t = t.append(y, ignore_index = True)
display(t)
display(t.dtypes)
|
Output

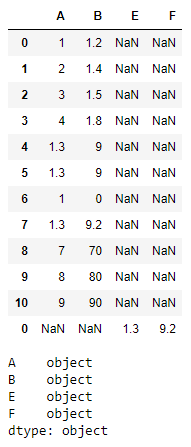
If we attempt to add different column than already in the data frame then results are as follows :
z = pd.DataFrame([["1.3", "9.2"]], columns = ["E", "F"])
t = t.append(z)
print(t)
print(t.dtypes)
print()
|
Output :
Share your thoughts in the comments
Please Login to comment...