Apache Kafka | Introduction
Last Updated :
08 Feb, 2018
Apache Kafka is a publish-subscribe messaging system. A messaging system let you send messages between processes, applications, and servers. Broadly Speaking, Apache Kafka is a software where topics (A topic might be a category) can be defined and further processed. Applications may connect to this system and transfer a message onto the topic. A message can include any kind of information ,from any event on your Personal blog or can be a very simple text message that would trigger any other event.
Kafka Broker
A Kafka cluster usually consists of one or more servers (called as kafka brokers), which are running Kafka over them. Producers are processes that publish data (push messages over trigger) into Kafka topics within the specified broker. A consumer of topics pulls messages off a Kafka topic.
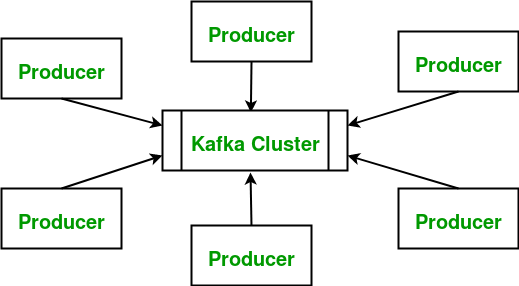
Kafka Topic : A Topic basically is a category or a feed name to which messages are stored and published during operations. Messages are mostly byte arrays that can store any object in any format. Yes , That’s the best thing about kafka. Any object can be stored as byte array. Also, as we discussed before, all Kafka messages are organized into topics. If you wish to send a message you send it to a specific topic and if you wish to read a message you read it from a specific topic.
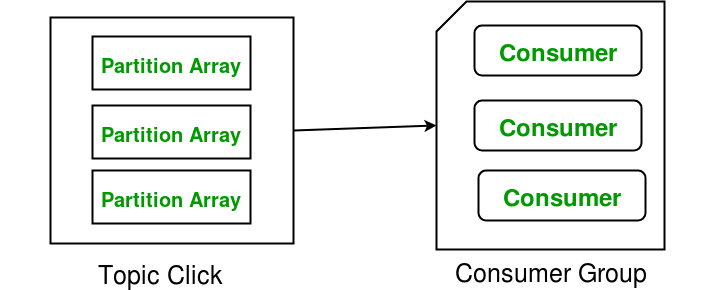
Consumers and consumer groups : Consumers can always read messages starting from a specific offset and are allowed to read from any offset point they choose in between. This allows consumers to join the cluster at any point in time.This makes functioning and working really smooth.
Partitions allow you to parallelise a topic by splitting the data in a particular topic across multiple brokers.
Apache Kafka and Important Server concepts
- Topic partition: Kafka topics are divided into a number of partitions, which allows you to split data across multiple brokers.
- Consumer Group: A consumer group includes the set of consumer processes that are subscribing to a specific topic.
- Node: A node is a single computer in the Apache Kafka cluster.
- Replicas: A replica of a partition is a “backup” of a partition. Replicas never read or write data. They are used to prevent data loss.
- Producer: Application that sends the messages.
- Consumer: Application that receives the messages.
Real time Applications
- Twitter: Registered users can read and post tweets, but unregistered users can only read tweets. Twitter uses Storm-Kafka as a part of their stream processing infrastructure.
- LinkedIn: Apache Kafka is used at LinkedIn for activity stream data and operational metrics. Kafka messaging system helps LinkedIn with various products like LinkedIn Newsfeed, LinkedIn Today for online message consumption and in addition to offline analytics systems like Hadoop.
- Netflix: Netflix is an American multinational provider of on-demand Internet streaming media. Netflix uses Kafka for real-time monitoring and event processing.
- Box: At Box, Kafka is used for the production analytics pipeline & real time monitoring infrastructure.
References :
Kafka official
Wiki
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...