10 Most Important Algorithms For Coding Interviews
Last Updated :
09 May, 2023
Algorithms are the set of rules to be followed in calculations or other problem-solving operations. It is considered one of the most important subjects considered from the programming aspect. Also, one of the most complex yet interesting subjects. From the interview aspect, if you want to crack a coding interview, you must have a strong command over Algorithms and Data Structures. In this article, we’ll read about some of the most important algorithms that will help you crack coding interviews.

There are many important Algorithms of which a few of them are mentioned below:
- Sorting Algorithms
- Searching Algorithms
- String Algorithms
- Divide and Conquer
- Recursion & Backtracking
- Greedy Algorithms
- Dynamic Programming
- Tree-Related Algo
- Graph Algorithms
- Sliding Window
|
Sorting algorithms are used to arrange the data in a specific order and use the same data to get the required information. Here are some of the sorting algorithms that are best with respect to the time taken to sort the data.

Sorting Algorithms
Below are the most important sorting algorithm as interview perspective:
- Bubble Sort
- Insertion Sort
- Selection Sort
- Quick Sort
- Heap sort
Searching Algorithms are designed to check for an element or retrieve an element from any data structure where it is stored.
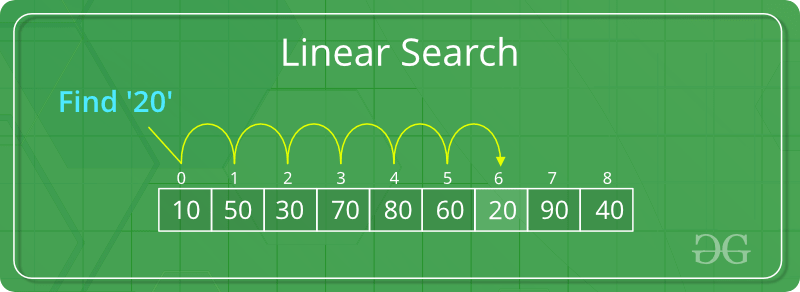
Searching Algorithms
- Linear Search
- Binary Search
The Pattern Searching algorithms are sometimes also referred to as String Searching Algorithms and are considered as a part of the String algorithms. These algorithms are useful in the case of searching a string within another string.
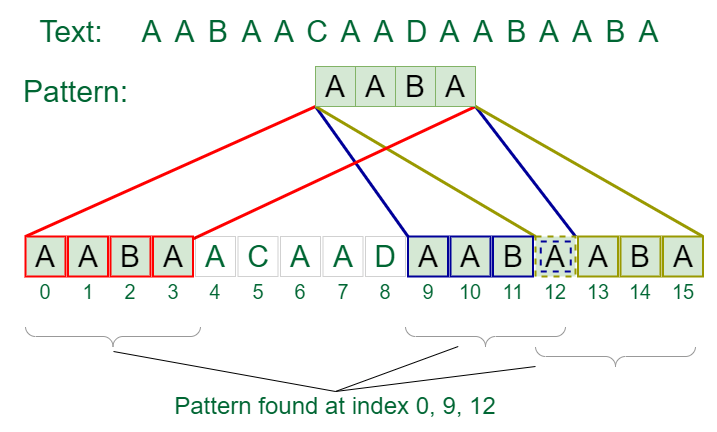
Pattern Searching Algorithms
- Rabin Karp Algorithm
- KMP Algorithm
- Z Algorithm
As the name itself suggests It’s first divided into smaller sub-problems then these subproblems are solved and later on these problems are combined to get the final solution. There are so many important algorithms that work on the Divide and Conquer strategy.
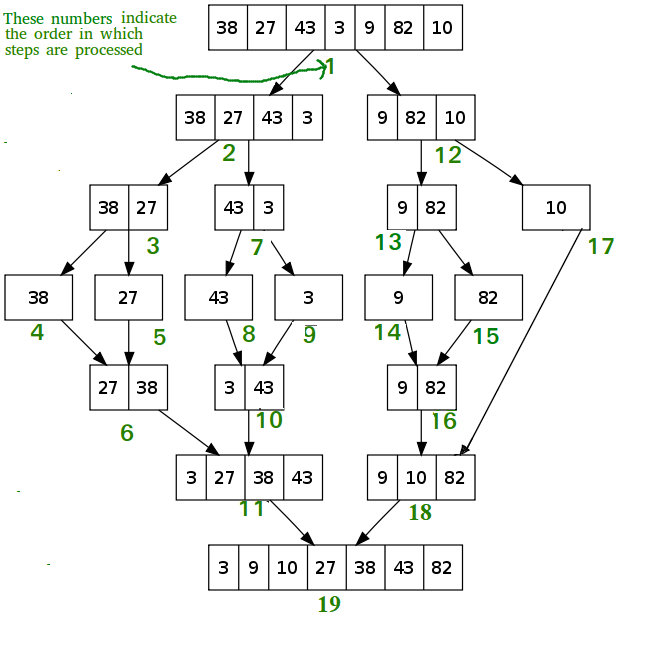
Divide and Conquer
Some examples of Divide and Conquer algorithms are as follows:
Backtracking is a variation of recursion. In backtracking, we solve the sub-problem with some changes one at a time and remove that change after calculating the solution of the problem to this sub-problem. It takes every possible combination of problems in order to solve them.
There are some standard questions on backtracking as mentioned below:
A greedy algorithm is a method of solving problems with the most optimal option available. It’s used in such situations where optimization is required i.e. where the maximization or the minimization is required.
Some of the most common problems with greedy algorithms are as follows –
Dynamic programming is one of the most important algorithms that is asked in coding interviews. Dynamic programming works on recursion. It’s an optimization of recursion. Dynamic Programming can be applied to all such problems, where we have to solve a problem using its sub-problems. And the final solution is derived from the solutions of smaller sub-problems. It basically stores solutions of sub-problems and simply uses the stored result wherever required, in spite of calculating the same thing again and again.
Some of the very important questions based on Dynamic Programming are as follows:
Tree traversal refers to the process of visiting all nodes in a tree data structure, typically in a specific order. In other words, it’s the method of accessing and processing each node in a tree in a systematic way.
here are different ways to traverse a tree, but the most common ones are:
- In-Order Traversal: In this traversal, the nodes are visited in the order of left subtree, root node, and right subtree. This type of traversal is commonly used in binary search trees.
- Pre-Order Traversal: In this traversal, the nodes are visited in the order of root node, left subtree, and right subtree.
- Post-Order Traversal: In this traversal, the nodes are visited in the order of left subtree, right subtree, and root node.
- Level-Order Traversal: It involves visiting each level of the tree from left to right. In this traversal, we start from the root node, visit all the nodes on the first level, then move to the second level and visit all the nodes on that level, and so on until we reach the last level.
- Breadth First Search (BFS): A graph traversal algorithm that explores all the vertices of a graph that are reachable from a given source vertex.
- Depth First Search (DFS): A graph traversal algorithm that explores all the vertices of a graph that are reachable from a given source vertex, by going as far as possible along each branch before backtracking.
- Dijkstra Algorithm: A shortest path algorithm that finds the shortest path between a given source vertex and all other vertices in a weighted graph.
- Floyd Warshall Algorithm: An all-pairs shortest path algorithm that finds the shortest path between all pairs of vertices in a weighted graph.
- Bellman-Ford Algorithm: A shortest path algorithm that can handle negative weight edges and detect negative weight cycles.
- Prim’s algorithm: A minimum spanning tree algorithm that finds the minimum spanning tree of a weighted, undirected graph.
- Kruskal’s algorithm: Another minimum spanning tree algorithm that finds the minimum spanning tree of a weighted, undirected graph.
Window Sliding Technique is a computational technique that aims to reduce the use of nested loops and replace it with a single loop, thereby reducing the time complexity.
There are several types of sliding window techniques, including:
Fixed-size sliding window: In this technique, the size of the window is fixed, and we move the window by one position at a time. This is often used to perform operations like finding the maximum or minimum value in a subarray of fixed size.
Variable-size sliding window: In this technique, the size of the window changes dynamically, depending on the problem constraints. This technique is often used to find the minimum or maximum subarray whose sum is greater than or equal to a certain value.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...