Learning Rate is an important hyperparameter in Gradient Descent. Its value determines how fast the Neural Network would converge to minima. Usually, we choose a learning rate and depending on the results change its value to get the optimal value for LR. If the learning rate is too low for the Neural Network the process of convergence would be very slow and if it’s too high the converging would be fast but there is a chance that the loss might overshoot. So we usually tune our parameters to find the best value for the learning rate. But is there a way we can improve this process?
Why adjust Learning Rate?
Instead of taking a constant learning rate, we can start with a higher value of LR and then keep decreasing its value periodically after certain iterations. This way we can initially have faster convergence whilst reducing the chances of overshooting the loss. In order to implement this we can use various scheduler in optim library in PyTorch. The format of a training loop is as following:-
epochs = 10
scheduler = <Any scheduler>
for epoch in range(epochs):
# Training Steps
# Validation Steps
scheduler.step()
Commonly used Schedulers in torch.optim.lr_scheduler
PyTorch provides several methods to adjust the learning rate based on the number of epochs. Let’s have a look at a few of them:–
- StepLR: Multiplies the learning rate with gamma every step_size epochs. For example, if lr = 0.1, gamma = 0.1 and step_size = 10 then after 10 epoch lr changes to lr*step_size in this case 0.01 and after another 10 epochs it becomes 0.001.
# Code format:-
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = StepLR(optimizer, step_size=10, gamma=0.1)
# Procedure:-
lr = 0.1, gamma = 0.1 and step_size = 10
lr = 0.1 for epoch < 10
lr = 0.01 for epoch >= 10 and epoch < 20
lr = 0.001 for epoch >= 20 and epoch < 30
... and so on
- MultiStepLR: This is a more customized version of StepLR in which the lr is changed after it reaches one of its epochs. Here we provide milestones that are epochs at which we want to update our learning rate.
# Code format:-
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = MultiStepLR(optimizer, milestones=[10,30], gamma=0.1)
# Procedure:-
lr = 0.1, gamma = 0.1 and milestones=[10,30]
lr = 0.1 for epoch < 10
lr = 0.01 for epoch >= 10 and epoch < 30
lr = 0.001 for epoch >= 30
- ExponentialLR: This is an aggressive version of StepLR in LR is changed after every epoch. You can think of it as StepLR with step_size = 1.
# Code format:-
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = ExponentialLR(optimizer, gamma=0.1)
# Procedure:-
lr = 0.1, gamma = 0.1
lr = 0.1 for epoch = 1
lr = 0.01 for epoch = 2
lr = 0.001 for epoch = 3
... and so on
- ReduceLROnPlateau: Reduces learning rate when a metric has stopped improving. Models often benefit from reducing the learning rate by a factor of 2-10 once learning stagnates. This scheduler reads a metrics quantity and if no improvement is seen for a patience number of epochs, the learning rate is reduced.
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = ReduceLROnPlateau(optimizer, 'min', patience = 5)
# In min mode, lr will be reduced when the metric has stopped decreasing.
# In max mode, lr will be reduced when the metric has stopped increasing.
Training Neural Networks using Schedulers
For this tutorial we are going to be using MNIST dataset, so we’ll start by loading our data and defining the model afterwards. Its recommended that you know how to create and train a Neural Network in PyTorch. Let’s start by loading our data.
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.ToTensor()
])
train = datasets.MNIST('',train = True, download = True, transform=transform)
valid = datasets.MNIST('',train = False, download = True, transform=transform)
trainloader = DataLoader(train, batch_size= 32, shuffle=True)
validloader = DataLoader(test, batch_size= 32, shuffle=True)
Now that we have our dataloader ready we can now proceed to create our model. PyTorch model follows the following format:-
from torch import nn
class model(nn.Module):
def __init__(self):
# Define Model Here
def forward(self, x):
# Define Forward Pass Here
With that clear let’s define our model:-
import torch
from torch import nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.fc1 = nn.Linear(28*28,256)
self.fc2 = nn.Linear(256,128)
self.out = nn.Linear(128,10)
self.lr = 0.01
self.loss = nn.CrossEntropyLoss()
def forward(self,x):
batch_size, _, _, _ = x.size()
x = x.view(batch_size,-1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.out(x)
model = Net()
# Send the model to GPU if available
if torch.cuda.is_available():
model = model.cuda()
Now that we have our model we can specify our optimizer, loss function and our lr_scheduler. We’ll be using SGD optimizer, CrossEntropyLoss for loss function and ReduceLROnPlateau for lr scheduler.
from torch.optim import SGD
from torch.optim.lr_scheduler import ReduceLROnPlateau
optimizer = SGD(model.parameters(), lr = 0.1)
loss = nn.CrossEntropyLoss()
scheduler = ReduceLROnPlateau(optimizer, 'min', patience = 5)
Let’s define the training loop. The training loop is pretty much the same as before except this time we’ll call our scheduler step method at the end of the loop.
from tqdm.notebook import trange
epoch = 25
for e in trange(epoch):
train_loss, valid_loss = 0.0, 0.0
# Set model to training mode
model.train()
for data, label in trainloader:
if torch.cuda.is_available():
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
target = model(data)
train_step_loss = loss(target, label)
train_step_loss.backward()
optimizer.step()
train_loss += train_step_loss.item() * data.size(0)
# Set model to Evaluation mode
model.eval()
for data, label in validloader:
if torch.cuda.is_available():
data, label = data.cuda(), label.cuda()
target = model(data)
valid_step_loss = loss(target, label)
valid_loss += valid_step_loss.item() * data.size(0)
curr_lr = optimizer.param_groups[0]['lr']
print(f'Epoch {e}\t \
Training Loss: {train_loss/len(trainloader)}\t \
Validation Loss:{valid_loss/len(validloader)}\t \
LR:{curr_lr}')
scheduler.step(valid_loss/len(validloader))
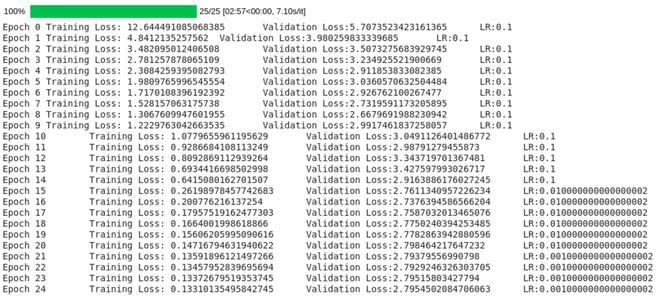
As you can see the scheduler kept adjusting lr when the validation loss stopped decreasing.
Code:
import torch
from torch import nn
import torch.nn.functional as F
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
from torch.optim import SGD
from torch.optim.lr_scheduler import ReduceLROnPlateau
from tqdm.notebook import trange
transform = transforms.Compose([
transforms.ToTensor()
])
train = datasets.MNIST('',train = True, download = True, transform=transform)
valid = datasets.MNIST('',train = False, download = True, transform=transform)
trainloader = DataLoader(train, batch_size= 32, shuffle=True)
validloader = DataLoader(test, batch_size= 32, shuffle=True)
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.fc1 = nn.Linear(28*28,64)
self.fc2 = nn.Linear(64,32)
self.out = nn.Linear(32,10)
self.lr = 0.01
self.loss = nn.CrossEntropyLoss()
def forward(self,x):
batch_size, _, _, _ = x.size()
x = x.view(batch_size,-1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.out(x)
model = Net()
if torch.cuda.is_available():
model = model.cuda()
optimizer = SGD(model.parameters(), lr = 0.1)
loss = nn.CrossEntropyLoss()
scheduler = ReduceLROnPlateau(optimizer, 'min', patience = 5)
epoch = 25
for e in trange(epoch):
train_loss, valid_loss = 0.0, 0.0
model.train()
for data, label in trainloader:
if torch.cuda.is_available():
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
target = model(data)
train_step_loss = loss(target, label)
train_step_loss.backward()
optimizer.step()
train_loss += train_step_loss.item() * data.size(0)
model.eval()
for data, label in validloader:
if torch.cuda.is_available():
data, label = data.cuda(), label.cuda()
target = model(data)
valid_step_loss = loss(target, label)
valid_loss += valid_step_loss.item() * data.size(0)
curr_lr = optimizer.param_groups[0]['lr']
print(f'Epoch {e}\t \
Training Loss: {train_loss/len(trainloader)}\t \
Validation Loss:{valid_loss/len(validloader)}\t \
LR:{curr_lr}')
scheduler.step(valid_loss/len(validloader))
|
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...