In the software engineering interview process system design round has become a standard part of the interview. The main purpose of this round is to check the ability of a candidate to build a complex and large-scale system. Due to the lack of experience in building a large-scale system a lot of engineers struggle with this round. There is no accurate and standard answer to the design problems. You may have different conversations with different interviewers for the same question. Due to the open-ended nature of this round, not just junior and mid-level developers but also experienced developers feel uncomfortable in this round.

This round is not much focused on coding. The interviewer wants to know how you architect the entire system and how you glue them together. If you are preparing yourself for this round then we recommend you to read the blog How to Crack System Design Round in Interviews. You should know some important system design concepts round before you jump into preparing yourself for some specific questions. We are going to cover some basic concepts of system design fundamentals code to build a strong foundation for the problems in this round.
1. Load Balancing
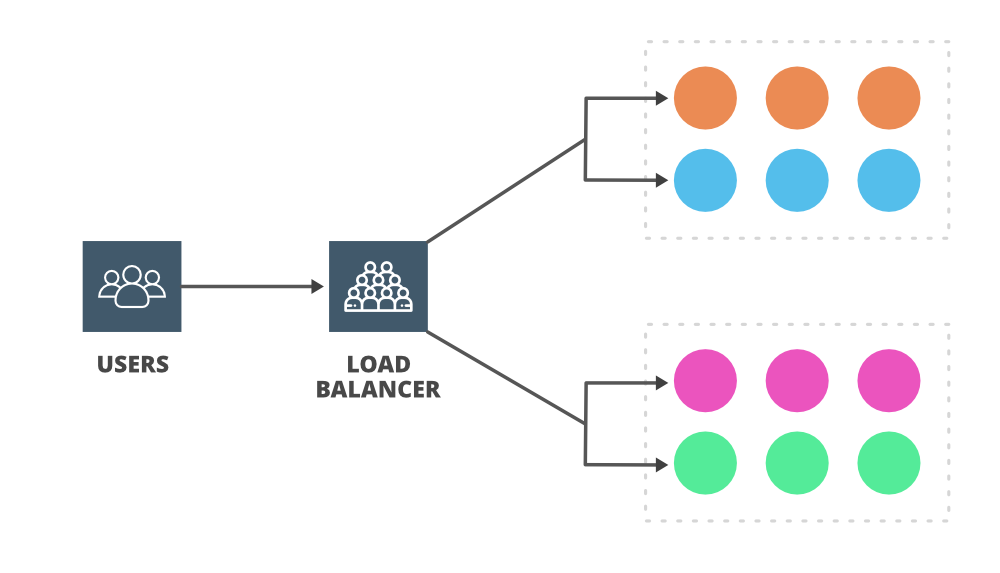
In a system, a server has a certain amount of capacity to handle the load or request from users. If a server receives a lot of requests simultaneously more than its capacity then the throughput of the server gets reduced and it can slow down. Also, it can fail (with no availability) if it continues for a longer period. You can add more servers (horizontal scaling) and resolve this issue by distributing the number of requests among these servers. Now the question is who is going to take ownership of distributing the request and balancing the load. Who is going to decide which request should be allocated to which server to ease the burden of a single server? Here comes the role of the load balancer.
A load balancer’s job is to distribute traffic to many different servers to help with throughput, performance, latency, and scalability. You can put the load balancer in front of the clients (it can be also inserted in other places) and then the load balancer will route the incoming request across multiple web servers. In short, load balancers are traffic managers and they take responsibility for the availability and throughput of the system. Nginx, Cisco, TP-Link, Barracuda, Citrix, and Elastic Load Balancing from AWS, are some popular load balancers available in the market.
2. Caching
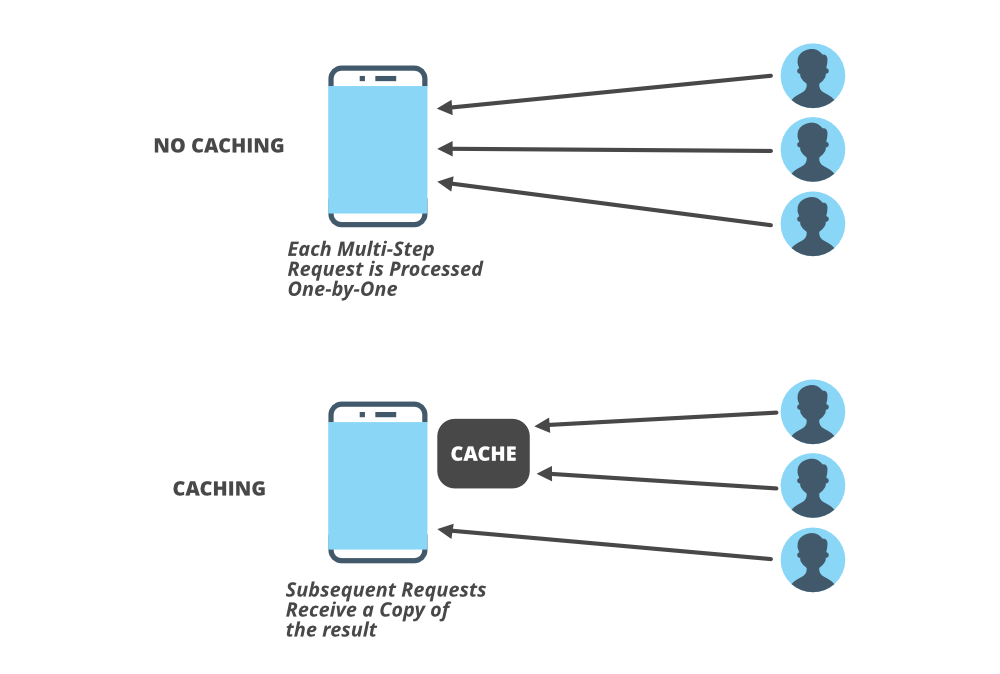
We talked about the load on the servers in the load balancing section but one thing you need to know is usually your web server is not the first to go down, in fact, quite often your database server may be under high loads for lots of writes or reads operations. Quite often we hit the database for various queries and joins which slows down the performance of the system. To handle these queries and lots of reads and writes caching is the best technique to use.
Do you go to your nearest shop to buy some essentials every time you need something in your kitchen? absolutely no. Instead of visiting the nearest shop every time we want to buy and store some basics in our refrigerator and our food cupboard. This is caching. The cooking time gets reduced if the food items are already available in your refrigerator. This saves a lot of time. The same things happen in the system. Accessing data from primary memory (RAM) is faster than accessing data from secondary memory (disk). By using the caching technique you can speed up the performance of your system.
If you need to rely on a certain piece of data often then cache the data and retrieve it faster from the memory rather than the disk. This process reduces the workload on the backend servers. Caching helps in reducing the network calls to the database. Some popular caching services are Memcache, Redis, and Cassandra. A lot of websites use CDN (content delivery network) which is a global network of servers. CDN caches static assets files like images, javascript, HTML, or CSS and it makes accessing very fast for the users. You can insert caching in on the client (e.g. browser storage), between the client and the server (e.g. CDNs), or on the server itself.
3. Proxies
Quite often you may have seen some notification on your PC to add and configure the proxy servers but what exactly proxy servers are and how does it work? Typically proxy servers are some bit of code or intermediary piece of hardware/software that sits between a client and another server. It may reside on the user’s local computer or anywhere between the clients and the destination servers. A proxy server receives requests from the client and transmits them to the origin servers, then forwards the received response from the server to the originator client. In some cases, when the server receives the request the IP address is not associated with the client but is of the proxy server. This happens when the proxy server hides the identity of the client.
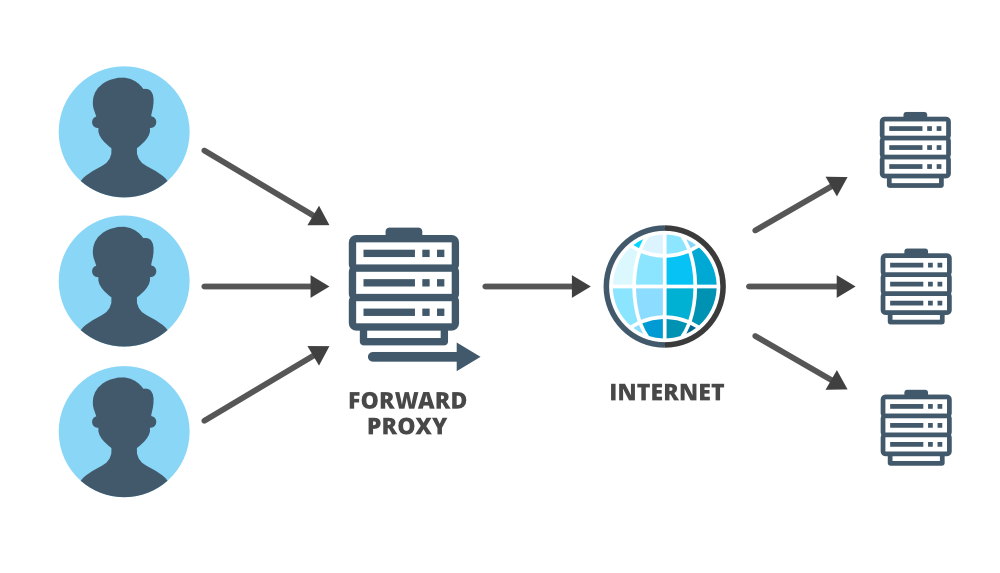
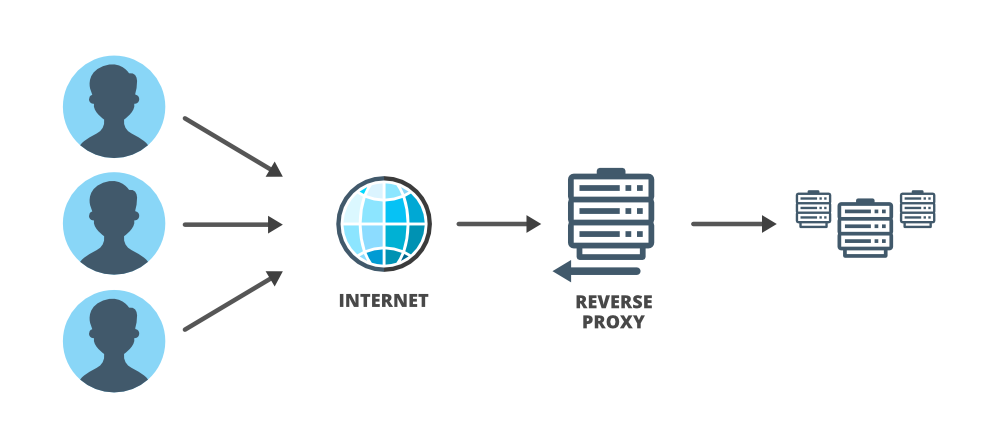
In general, when people use the term proxy they refer to ‘forward proxy’. ‘Forward proxy’ is designed to help users and it acts on behalf of (substitute for) the client in the interaction between client and server. It forwards the user’s requests and acts as a personal representative of the user. In system design, especially in complex systems, proxies are very useful, particularly ‘reverse proxies’ are useful. ‘Reverse proxies’ are the opposite of ‘forward proxies’. A reverse proxy acts on behalf of a server and is designed to help servers.
In the ‘forward proxy’ server won’t know that the request and response are routed through the proxy, and in a reverse proxy, the client won’t know that the request and response are traveling through a proxy. A ‘reverse proxy’ can be assigned a lot of tasks to help the main server and it can act as a gatekeeper, a screener, a load-balancer, and an all-around assistant.
Typically proxies are used to handle requests, filter requests or log requests, or sometimes transform requests (by adding/removing headers, encrypting/decrypting, or compression). It helps in coordinating requests from multiple servers and it can be used to optimize request traffic from a system-wide perspective.
Forward Proxy:
Reverse Proxy:
4. CAP Theorem
CAP stands for Consistency, Availability, and Partition tolerance. The theorem states that you cannot achieve all the properties at the best level in a single database, as there are natural trade-offs between the items. You can only pick two out of three at a time and that totally depends on your priorities based on your requirements. For example, if your system needs to be available and partition tolerant, then you must be willing to accept some latency in your consistency requirements. Traditional relational databases are a natural fit for the CA side whereas Non-relational database engines mostly satisfy AP and CP requirements.
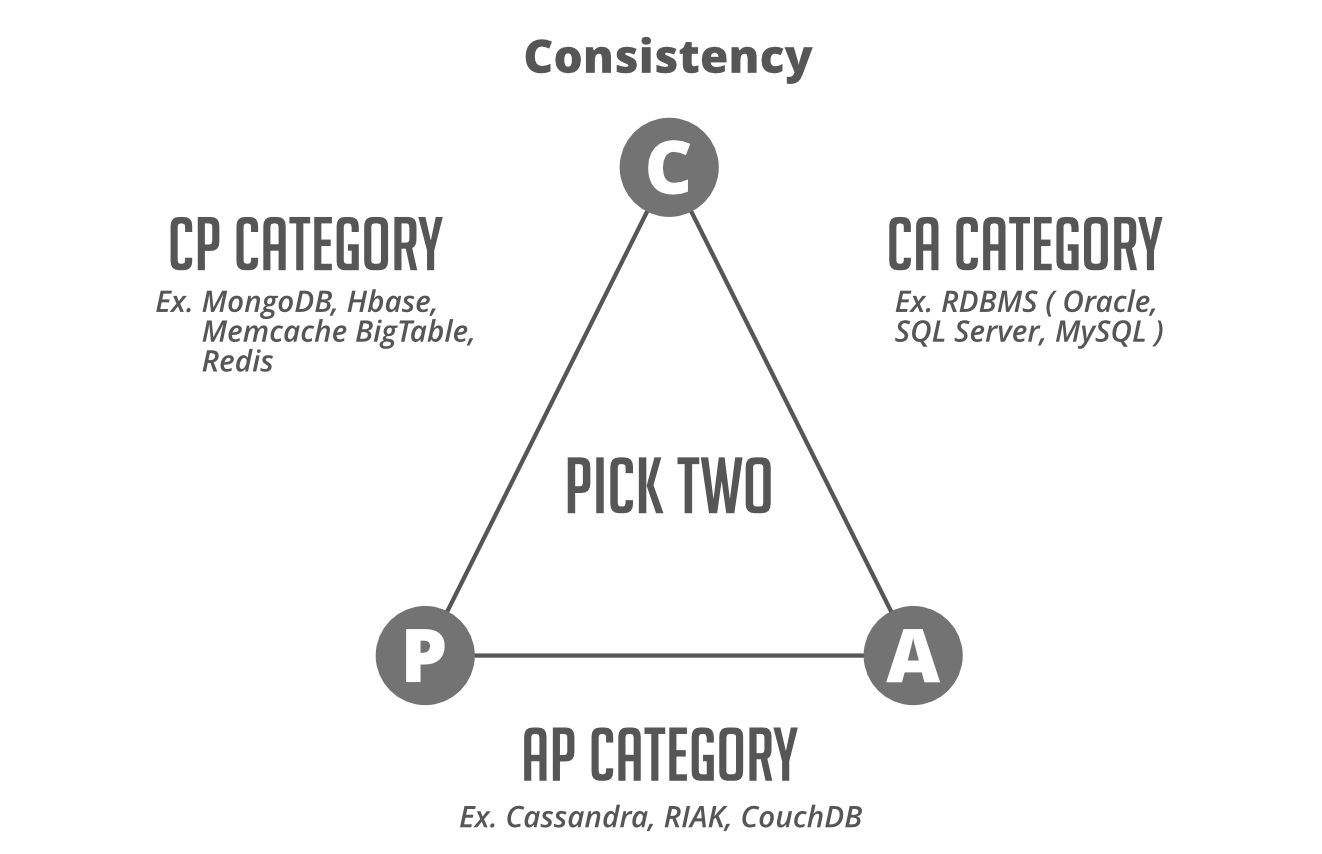
- Consistency means that any read request will return the most recent write. Data consistency is usually “strong” for SQL databases and for NoSQL databases consistency may be anything from “eventual” to “strong”.
- Availability means that a non-responding node must respond in a reasonable amount of time. Not every application needs to run 24/7 with 99.999% availability but most likely you will prefer a database with higher availability.
- Partition tolerance means the system will continue to operate despite network or node failures.
Keep in mind this CAP theorem in your system design interview. Take the decision depending on the type of application and your priorities. Is it actually ok if your system goes down for a few seconds or a few minutes, if not then availability should be your prime concern. If you’re dealing with something with real transactional information like a stock transaction or financial transaction you might value consistency above all. Try to choose the technology that is best suited to the trade-offs that you want to make.
Note: CA systems are not defined for distributed systems. However, in the case of a single node setup, you can get CA capabilities. Further, distributed systems have to support partition tolerance due to network failures. Hence, either you choose Consistency or Availability i.e. build a CP or an AP system.
5. Databases
In the system design interviews, it’s not uncommon that ought to be asked to design the database schema about what tables you may be using. what the primary key is going to look like and what are your indices? You also need to choose the different types of storage solutions (relational or non-relational) designed for different use cases. We are going to discuss some important concepts of databases that are frequently used in system design.
- Database Indexing: Database indexes are typically a data structure that facilitates the fast searching of databases..but how? let’s understand with an example. Suppose you have a database table with 200 million rows and this table is used to look up one or two values in each record. Now if you need to retrieve a value from a specific row then you need to iterate over the table which can be a time-consuming process especially if it’s the last record in the table. We can use indexing for these kinds of problems.
Basically, indexing is a way of sorting a number of records on multiple fields. When you add an index in a table on a field, it creates another data structure that holds the field value and a pointer to the record it relates to. This index structure is then sorted, allowing binary searches to be performed on it. If you have 200 million records in a table with names and ages and you want to retrieve lists of people belonging to an age group, then you need to add an index on the age attribute into the database. Read more about this topic from the link Indexing in the database.
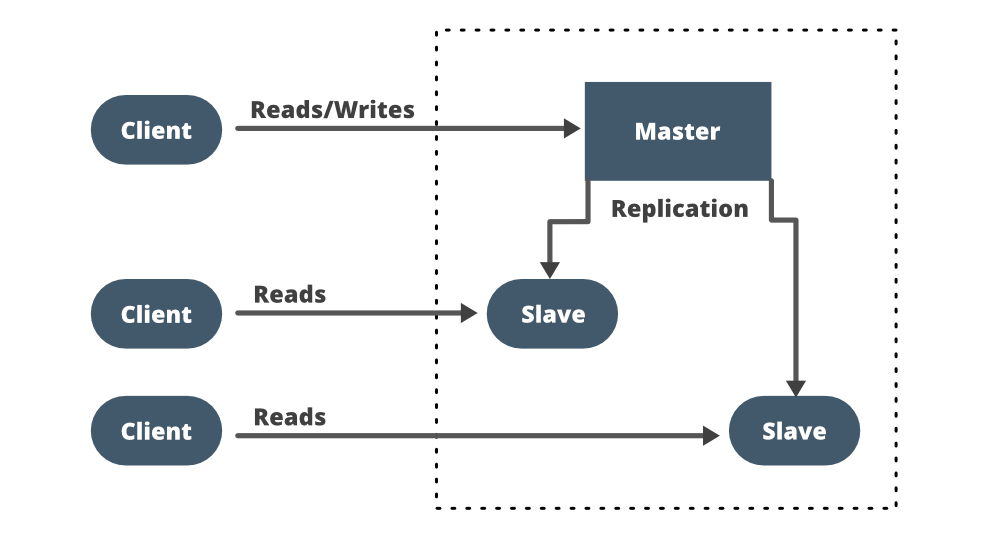
- Replication: What will happen if your database handles so much load? It will crash at a certain point and your entire system will stop working because all the requests depend on data in the servers. To avoid this kind of failure we use replication which simply means duplicating your database (master) and allowing only read operations on these replicas (slave) of your database. Replication solves the availability issue in your system and ensures redundancy in the database if one goes down. You created the replica (slave) of your database but how would you pull the data from the original (master) database? how would you synchronize the data across the replicas, since they’re meant to have the same data?
You can choose a synchronous (at the same time as the changes to the main database) or an asynchronous approach depending on your needs. If it’s asynchronous then you may have to accept some inconsistent data because changes in the master database may not reflect in the slave before it crashes. If you need the state between the two databases to be consistent then the replication needs to be rapid and you can go with a synchronous approach. You also need to ensure that if the write operation to the replica fails, the write operation to the main database also fails (atomicity).
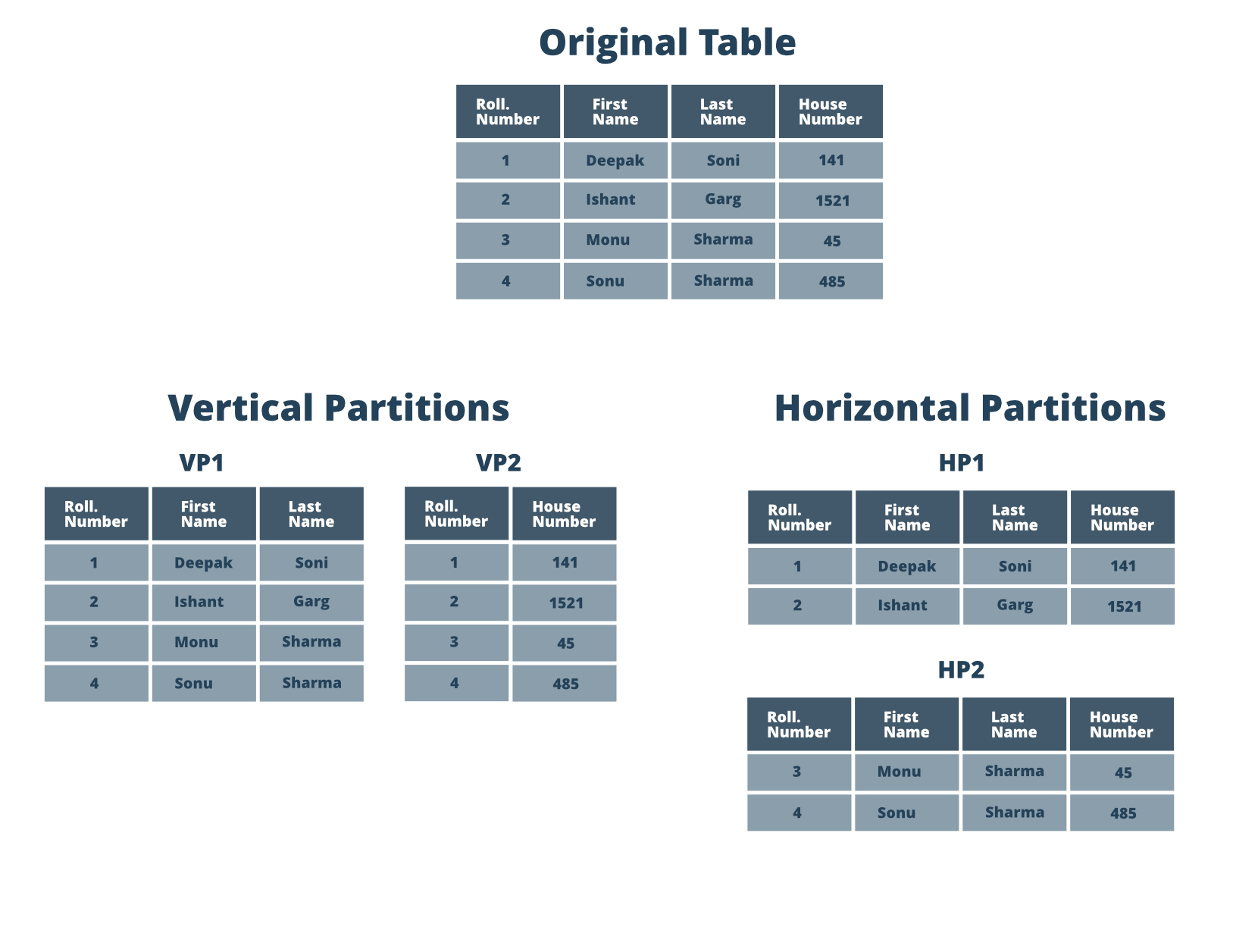
- Sharding or Data Partitioning: Replication of data solves the availability issue but it doesn’t solve the throughput and latency issues (speed). In those cases, you need to share your database which simply means ‘chunking down’ or partitioning your data records and storing those records across multiple machines. So sharding data breaks your huge database into smaller databases. Take the example of Twitter where a lot of writing is performed. To handle this case you can use database sharding where you split up the database into multiple master databases.
There are mainly two ways to shard your database- horizontal sharding and vertical sharding. In vertical sharding, you take each table and put each table into a new machine. So if you have a user table, a tweets table, a comments table, and a user supports table then each of these will be on different machines. Now, what if you have a single tweet table and it is very large? In that case, you can use horizontal sharding where you take a single table and you split that across multiple machines. You can take some sort of key like a user ID you can break the data into pieces and then you can allocate data to different machines. So horizontal partitioning depends on one key which is an attribute of the data you’re storing to partition data.
Want to get a Software Developer/Engineer job at a leading tech company? or Want to make a smooth transition from SDE I to SDE II or Senior Developer profiles? If yes, then you’re required to dive deep into the System Design world! A decent command over System Design concepts is very much essential, especially for working professionals, to get a much-needed advantage over others during tech interviews and get real code examples.
And that’s why, GeeksforGeeks is providing you with an in-depth interview-centric Mastering System Design Course that will help you prepare for the questions related to System Designs for Google, Amazon, Adobe, Uber, and other product-based companies.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...