How ranking in Google Search Works !
Last Updated :
01 Dec, 2023
You may first like to read:
How Google Search Works!
Let’s now have a look at some important terminology:
Search Engine:
A program that searches for and identifies items in a database that corresponds to keywords or characters specified by the user, used especially for finding particular sites on the World Wide Web. Example: Google search engine, Yahoo, Bing etc.
Search Engine Index:
A search engine index is a database that correlates keyword and websites so that the search engine can display websites that match a user’s search query. For example, if a user searches for Cheetah running speed, then the software spider searches these terms in the search engine index.
Web crawler:
The first thing you need to understand is what a Web Crawler or Spider is and how it works. A Search Engine Spider (also known as a crawler, Robot, SearchBot or simply a Bot) is a program that most search engines use to find what’s new on the Internet. Google’s web crawler is known as GoogleBot. The program starts at a website and follows every hyperlink on each page. So it can be said that everything on the web will eventually be found and spidered, as the so called “spider” crawls from one website to another. When a web crawler visits one of your pages, it loads the site’s content into a database. Once a page has been fetched, the text of your page is loaded into the search engine’s index, which is a massive database of words, and where they occur on different web pages.
Web crawlers crawls on few websites without approval. Therefore every website includes a robots.txt file which contains instructions for the spider(web crawler) on which parts of the website to index, and which parts to ignore.
PageRank algorithm
PageRank works by counting the number and quality of links to a page to determine rough estimation of how important the webpage is. When a web crawler goes through each website, it follows all the links in the website,and checks for how many links are connected to each site. And then it assigns percentage to each webpage which represents the importance of the webpage using page rank algorithm. For example, if there are three webpages named A, B and C.
Suppose if the number of links that connect to B are from five webpages which have less percentage and to C webpage has the link from A which has higher percentage, since the one link to C comes from a important page and hence C is given higher value than B.
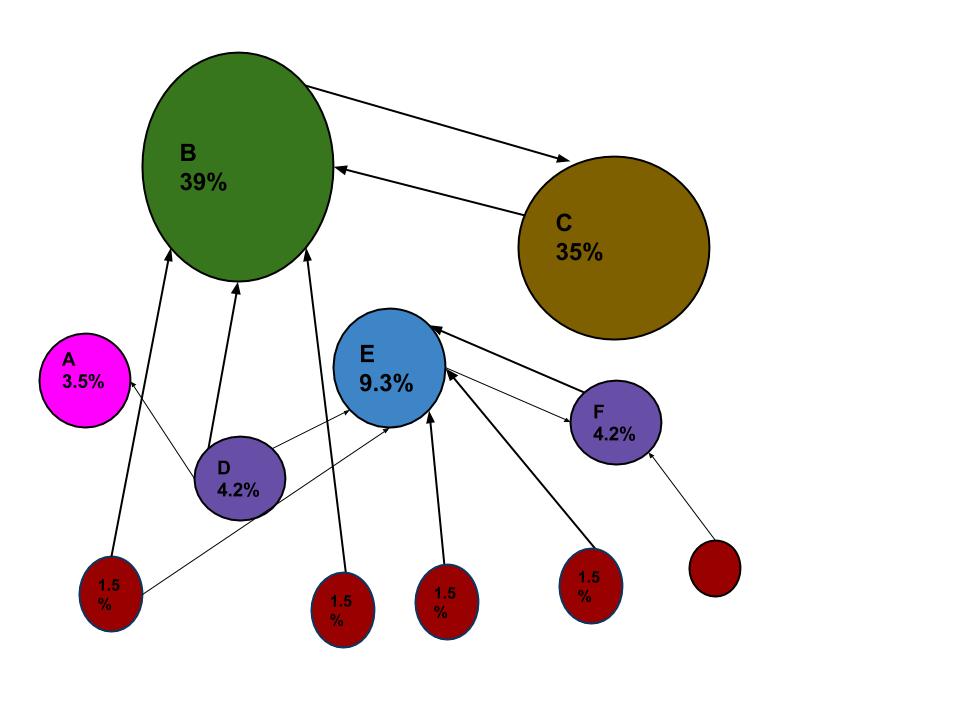
PageRank in graph of URLs is a probability distribution used to represent the likelihood that a person randomly clicking on links will arrive at any particular page.
So there are basically three steps that are involved in the web crawling procedure. First, the search bot starts by crawling the pages of your site. Then it continues indexing the words and content of the site, and finally it visits the links (web page addresses or URLs) that are found in your site
Importance of “robots.txt”
The first thing a spider is supposed to do when it visits your website, then it looks for a file called “robots.txt”. This file contains instructions for the spider on which parts of the website to index, and which parts to ignore. The only way to control what a spider sees on your site is by using a robots.txt file. All spiders are supposed to follow some rules, and the major search engines do follow these rules for the most part.
Fortunately, the major search engines like Google or Bing are finally working together on standards. When you search, spider searches index to find every page that includes those search terms. In this case, it finds hundreds or thousands of pages and google decide which few documents are really wanted by asking questions more than 200 of them like:
- How many times does the page contains this keyword?
- Do the words appear in the title, in the URL, directly adjacent?
- Does the page include synonyms for these words?
- Is this page a quality website or low quality?
And then it fetches hundreds of web pages and ranks these importance of web pages by using the PageRank algorithm which looks at how many outside links point to it and how important those links are? Finally, it combines all those factors together to produce each page overall score and send back the search results in about a half a second after submitting the search. Each page includes the title, URL, snippet of the text to decide is that the particular page we are looking for. And if not relevant, it also display related searches at the bottom of the page.
Related Articles:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...